Software Enterprise: o que muda quando o produto precisa operar como plataforma
Escala, disponibilidade, compliance e integração deixam de ser “extras” e viram requisitos de sobrevivência. Um guia prático sobre os trade-offs e decisões que separam um sistema comum de uma plataforma enterprise.
software
architecture
enterprise
plataforma
Ednaldo Luiz
Nível: Intermediário
Nível:
Publicado:
Última atualização:
Recomendados
Conteúdos relacionados a software enterprise e arquitetura enterprise.
Engenheiro de Software focado em arquitetura e performance. Trabalho com Java/Spring Boot, SQL bem estruturado, serviços escaláveis na AWS e soluções GenAI com RAG (LangChain + bases vetoriais). Valorizo código legível e decisões bem justificadas.
Quando um produto vira plataforma, ele deixa de atender um time e passa a sustentar vários consumidores ao mesmo tempo: áreas internas, integrações, automações, parceiros e até outros produtos.
Todo SaaS quer chegar nesse ponto. Só que aqui muda o jogo: decisões que eram “boas o suficiente” quando o foco era entregar rápido começam a cobrar juros em operação, custo e risco.
Entregar feature rápido não é o problema. Isso é normal — e muitas vezes necessário para crescer. O problema é quando a dívida técnica deixa de ser incômodo e vira risco real de negócio: um incidente pequeno passa a afetar faturamento, atendimento, compliance ou a operação de alguém do outro lado.
A partir daí, a pergunta não é mais “como entregar mais rápido”.
Ela vira outra: como operar sem quebrar, mantendo custo, risco e evolução sob controle.
E um ponto importante: não existe uma definição formal universal de “software enterprise”. Não é um selo técnico. É um contexto — um tipo de ambiente onde as restrições são reais e forçam decisões diferentes.
Como eu tantas vezes tenho que dizer, não existe uma definição formal para este termo.
Neste artigo, a ideia é organizar o que na prática chamam de software enterprise e mostrar por que escolhas que pareciam pequenas começam a cobrar caro quando o produto deixa de ser só software e passa a sustentar trabalho real.
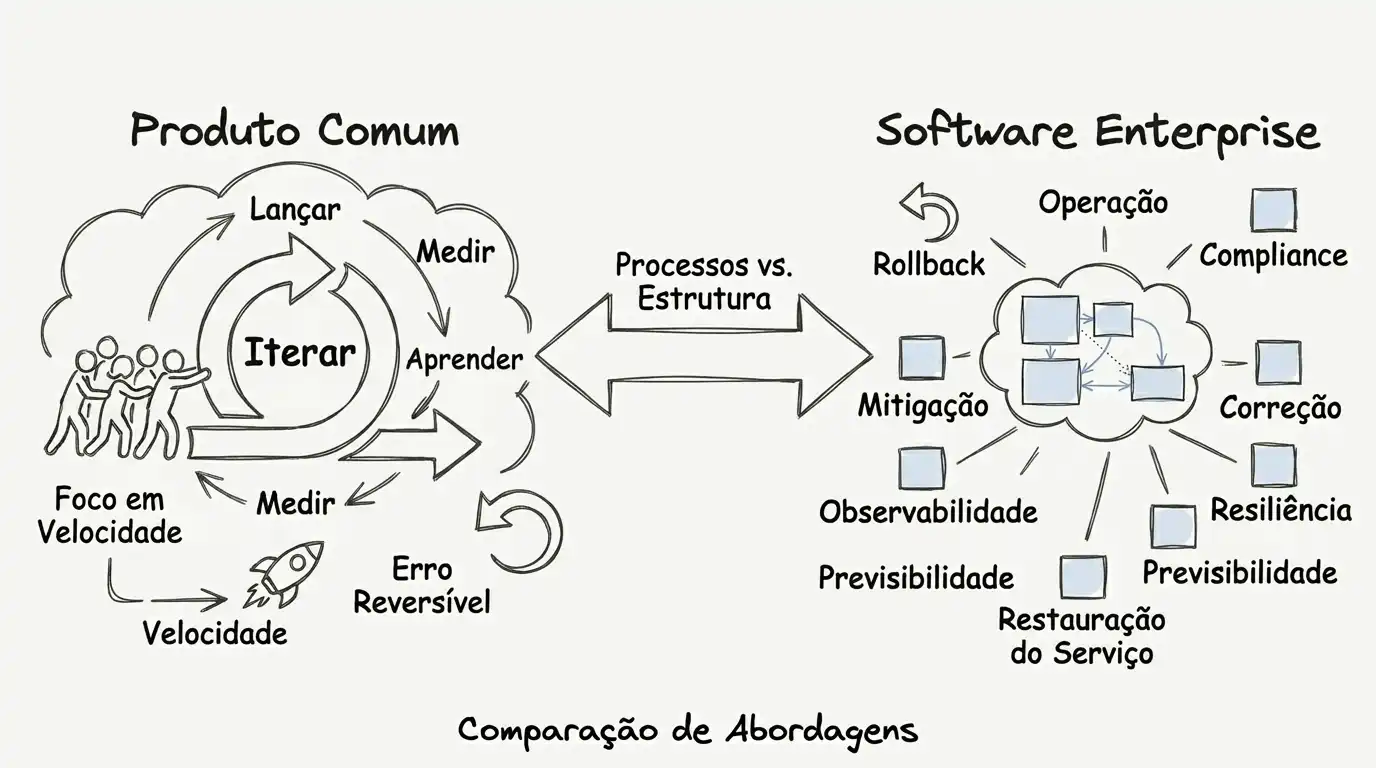
Antes de falar em software enterprise, vale alinhar o básico: o que é um produto.
Produto, na prática, é uma solução que existe para entregar valor rápido e melhorar com uso real. O loop é simples: lançar → medir → corrigir → repetir. Nessa fase, errar é tolerável porque o impacto costuma ser contido — você consegue reverter, corrigir e seguir em frente.
Software enterprise aparece quando esse mesmo produto vira base de trabalho. Ele passa a sustentar operação, contratos, integrações e decisões de negócio.
Aí muda o jogo: você otimiza para previsibilidade — risco controlado, integração confiável, segurança e evolução sem susto. Porque aqui erro não vira “só bug”. Vira incidente.
Se quiser explorar melhor essa distinção, veja nosso artigo sobre .
A diferença central não é o tamanho do sistema. É o quanto a operação, o cliente e o negócio dependem dele para funcionar.
Vale um ajuste importante: nem todo produto grande vira software enterprise, e nem só bancos, hospitais ou governos entram nessa categoria.
Isso também ajuda a separar duas coisas que muita gente mistura: categoria e contexto.
Um sistema pode nascer em um domínio que costuma virar enterprise — como jurídico, saúde ou finanças — e ainda assim, no estágio inicial, não carregar esse peso todo.
Do mesmo jeito, um produto enorme também não vira enterprise só porque cresceu. Sem operação crítica, integração sensível e consequência real de negócio, tamanho sozinho não basta.
O que empurra um sistema para esse terreno não é só escala nem setor.
É o momento em que ele passa a sustentar operação crítica, integrações, governança e risco real de negócio. Em outras palavras: não é tamanho — é consequência.
A pergunta prática, então, não é “qual stack eu uso?” nem “quantos usuários eu tenho?”.
É outra: em que momento esse sistema deixa de ser só produto e passa a segurar a operação no dia a dia?
quebra operação (fila trava, time interno não consegue trabalhar)
vira incidente de suporte (atendimento lota, estoura)
encosta em compliance (auditoria, LGPD, trilha de acesso)
ou cria risco reputacional (cliente grande cobrando explicação)
A partir daí, “funciona no meu ambiente” deixa de ser aceitável por um motivo simples: ambiente real é produção — com dados reais, carga real, integrações reais e gente dependendo.
Se roda na sua máquina, mas falha no mundo real, isso não vale quase nada. Cliente, suporte, operação, liderança e quem responde pelo negócio não querem saber se “aqui funcionou”. O que importa é outra coisa: funciona em produção, com previsibilidade, risco controlado e sem susto.
O foco muda:
antes: entregar mais
depois: entregar com confiabilidade
e, principalmente: não quebrar o que já está de pé
No fim das contas, o que empurra um software para o terreno enterprise não é o tamanho. É o nível de dependência, risco e consequência que ele passa a carregar.
Quando o sistema passa a sustentar operação de verdade, o jeito de decidir muda.
Decisão técnica deixa de ser só uma escolha de implementação e vira também uma escolha de risco, custo e continuidade.
Por isso, algumas prioridades sobem para o topo:
Contratos e compatibilidade
API, eventos e integrações deixam de ser detalhe interno. Você precisa pensar em versionamento, e impacto de mudança antes de publicar qualquer coisa.
Observabilidade
Sem logs úteis, métricas, alertas e , você não opera — você adivinha. E sistema crítico não pode depender de adivinhação.
Segurança por padrão
Autorização consistente, trilha de auditoria e menor privilégio deixam de ser “refinamento”. Viram requisito básico para reduzir exposição e responder por acesso, ação e dado.
Resiliência
Timeout, retry com critério, e degradação controlada passam a importar porque dependência externa falha, fila atrasa e rede oscila. O sistema precisa continuar útil mesmo quando algo ao redor quebra.
Processo de entrega
CI/CD, testes confiáveis, e migração segura deixam de ser luxo de time organizado. São o que impede deploy de virar incidente.
E é justamente aí que entra a próxima pergunta: o que sustenta esse tipo de software no dia a dia?
Software enterprise não se sustenta só com arquitetura bonita ou stack moderna.
O seu framework JS favorito não é o que vai salvar a operação quando o sistema virar plataforma.
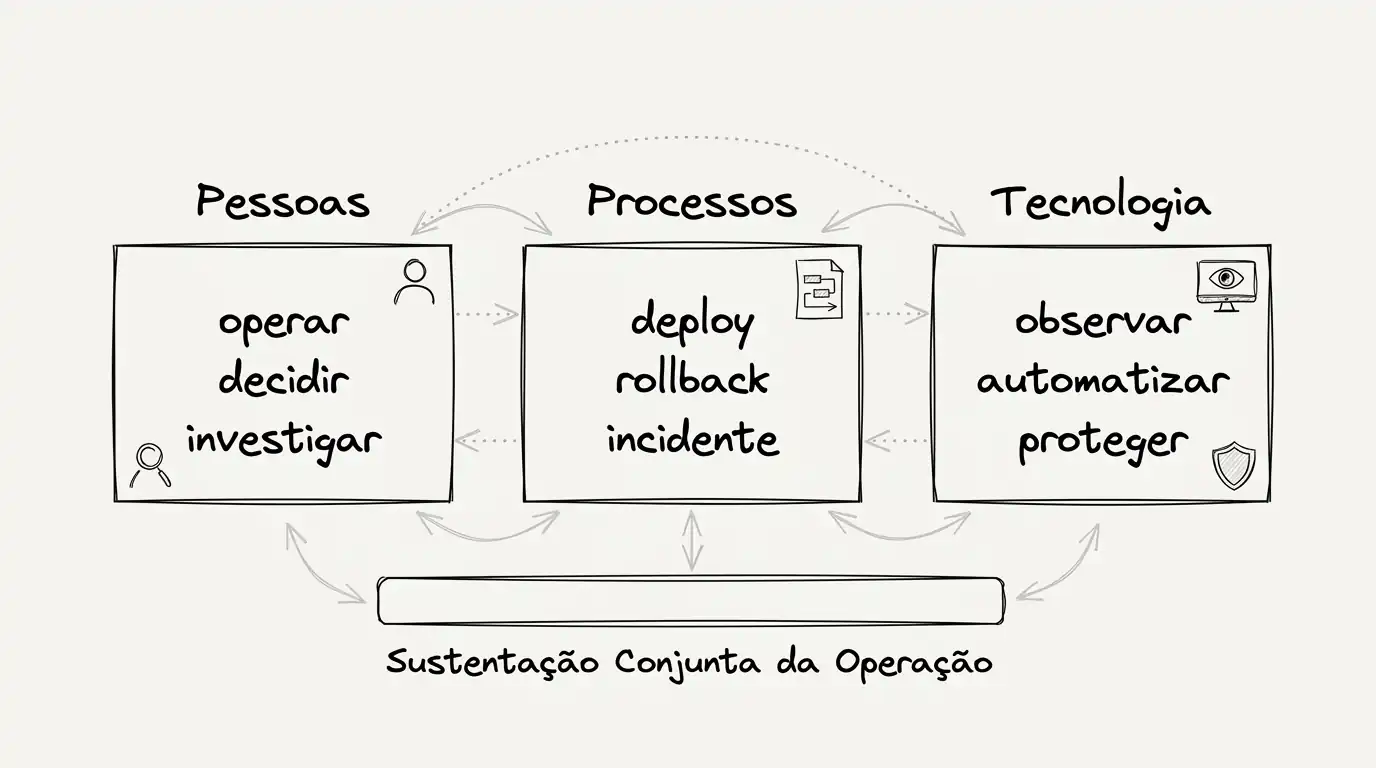
Na prática, ele se apoia em três pilares que precisam funcionar juntos: pessoas, processos e tecnologia.
Se um deles falha, o sistema perde previsibilidade.
Se dois falham, a operação vira improviso.
Se os três falham ao mesmo tempo, o problema já não é técnico — é organizacional.
Pessoas operam, investigam, decidem e tomam a frente quando algo sai do normal.
Sem gente que entende o domínio, os fluxos críticos e os riscos do sistema, qualquer incidente vira caos.
Processos existem para fazer o time agir de forma previsível e segura, sem improvisar o tempo todo.
Deploy, rollback, gestão de incidente, revisão de mudança, acesso à produção e resposta a falhas não podem depender de memória ou boa vontade.
Tecnologia entra para sustentar isso bem: observar, automatizar, proteger, integrar e recuperar.
Mas ferramenta sozinha não segura operação. Software enterprise se sustenta quando gente preparada, processo claro e tecnologia útil trabalham na mesma direção.
Para uns, governança é burocracia.
Na prática, é ela que cria o mínimo de alinhamento necessário para que autonomia não vire bagunça e velocidade não vire risco.
É governança que define limites, responsabilidades e padrões mínimos antes que a complexidade fuja do controle.
Governança responde perguntas que times enterprise não podem deixar no ar:
quem pode mudar o quê
quem aprova mudança crítica
como versionar contrato sem quebrar consumidor
como tratar incidente, exceção e acesso sensível
quais padrões são obrigatórios e quais são só recomendação
Sem isso, o sistema até cresce — mas cresce torto:
cada time decide de um jeito
cada módulo nasce com a stack que o time prefere, sem olhar o ecossistema
cada integração cria sua própria regra — e o que poderia existir como um ponto confiável acaba sendo refeito em vários lugares
cada incidente vira discussão sobre — e às vezes sobre culpa
No começo, isso parece autonomia.
Com o tempo, vira atrito, inconsistência e uma operação muito mais frágil do que deveria.
E quando esses pilares não se sustentam bem, os requisitos de operação passam a mandar no jogo.
Escalabilidade não é só aguentar mais carga.
É crescer sem destruir latência, custo ou operação no processo.
Em software enterprise, isso importa porque o sistema quase nunca cresce sozinho: cresce junto com integrações, dados, consumidores, picos de uso e novas dependências.
Escalar bem não é só colocar mais máquina.
É continuar respondendo com previsibilidade quando o contexto fica maior e mais pesado.
Escalar mal não é só perder performance.
Às vezes é transformar crescimento em custo, atrito e operação sofrida.
Sistema online não impressiona ninguém quando a função que importa continua falhando.
Disponibilidade não é só servidor ligado.
Disponibilidade de verdade é a funcionalidade certa estar acessível quando o negócio precisa dela.
Se o login funciona, mas o módulo principal não, para o usuário o sistema está indisponível.
Em enterprise, disponibilidade é percebida pela operação, não pelo dashboard da infra.
Segurança aqui não é detalhe de implementação.
É controle de acesso, trilha de auditoria, proteção de dado e capacidade de responder por quem fez o quê.
Compliance entra no mesmo pacote: em muitos contextos, não basta funcionar.
Tem que funcionar do jeito certo, com rastreabilidade, regra clara e responsabilidade definida.
Quando o sistema sustenta operação real, segurança deixa de ser “camada extra”.
Ela vira parte do contrato de funcionamento do negócio.
Em enterprise, integração não é detalhe.
É o que naturalmente acontece quando o sistema cresce.
O sistema precisa conversar com legado, parceiros, fornecedores, , , e fluxos internos.
A pergunta nunca é “se vai integrar”.
É como integrar sem espalhar acoplamento, duplicação de regra e fragilidade pelo caminho.
Outro ponto crítico é não colar regra de negócio na API de um fornecedor específico.
Quando isso acontece, trocar provedor vira quase reescrever fluxo crítico. O ideal é isolar integrações por contratos claros e adaptadores, mantendo o domínio estável mesmo quando o parceiro muda.
Se você não enxerga o sistema, você não opera o sistema.
Você reage no escuro.
Logs, métricas, alertas e tracing são o que permitem entender comportamento, investigar falha e reagir com velocidade.
Em ambiente enterprise, caixa-preta é risco operacional.
Se você não consegue enxergar o que está acontecendo, não consegue decidir direito nem corrigir rápido.
E tem um erro comum aqui: achar que ausência de reclamação significa ausência de problema. Muita falha passa sem reporte, ou nem chega a ser percebida pelo cliente, e fica escondida até virar incidente maior.
Enterprise quase sempre exige duas coisas ao mesmo tempo: padronização para operar bem e flexibilidade para atender realidades diferentes.
Se você padroniza tudo, trava o negócio.
Se adapta tudo sem critério, destrói manutenção.
Isso também vale para a decisão entre construir e depender de terceiros.
Nem tudo faz sentido criar do zero — mas terceirizar demais pode custar controle, velocidade e diferencial.
O ponto saudável está no meio: padronizar o que precisa ser comum, adaptar o que realmente diferencia e modularizar o sistema para que essa variação não vire bagunça.
Sem limite claro, o que era exceção vira regra — e a manutenção degrada.
Em software enterprise, a aplicação raramente é a única coisa crítica.
Muitas vezes, o ativo mais valioso é o dado que ela carrega, preserva e movimenta.
Por isso, evoluir o sistema não é só mudar código.
É também proteger integridade, histórico, compatibilidade e migração sem transformar a base em risco operacional.
Mudar uma regra de negócio no código costuma ser rápido.
Difícil é garantir que o dado antigo continue fazendo sentido depois da mudança.
Quando isso quebra, normalmente não quebra de forma visível no código primeiro.
Quebra no histórico, na integração e na confiança sobre o que o sistema sabe.
Quando esse cuidado falta, o problema aparece rápido:
regra muda, mas o dado antigo continua no formato anterior
integração nova interpreta informação de outro jeito
histórico deixa de bater com o presente
migração vira aposta
auditoria encontra dado, mas ninguém consegue explicar a trajetória dele
Em enterprise, dado não é só armazenamento.
É memória operacional, contrato entre sistemas e evidência do que já aconteceu.
Quando dado vira ativo crítico, toda decisão técnica fica mais cara de desfazer.
E é aí que os trade-offs deixam de ser teoria.
Quando o software entra de vez no terreno enterprise, arquitetura deixa de ser só organização de código.
Ela passa a ser também uma forma de controlar risco, preservar operação e sustentar evolução sem colapsar o que já funciona.
Na prática, isso muda três decisões o tempo todo: quão simples você pode continuar, quando vale separar e o que realmente precisa acontecer em tempo real.
Simplicidade quase sempre ganha no começo.
Ela reduz atrito, acelera entrega e torna o sistema mais fácil de entender, operar e corrigir.
O erro é confundir simplicidade com ingenuidade.
Arquitetura simples demais, sem olhar para crescimento, integração e carga real, pode quebrar cedo quando o sistema começa a sustentar operação de verdade.
Do outro lado, escalar antes da hora também custa caro.
Camadas demais, serviços demais e abstração demais atrasam entrega e colocam complexidade onde ainda não existe problema real.
O ponto saudável é simples: comece com a solução mais simples que suporta o contexto atual, mas sem fechar as portas para evolução.
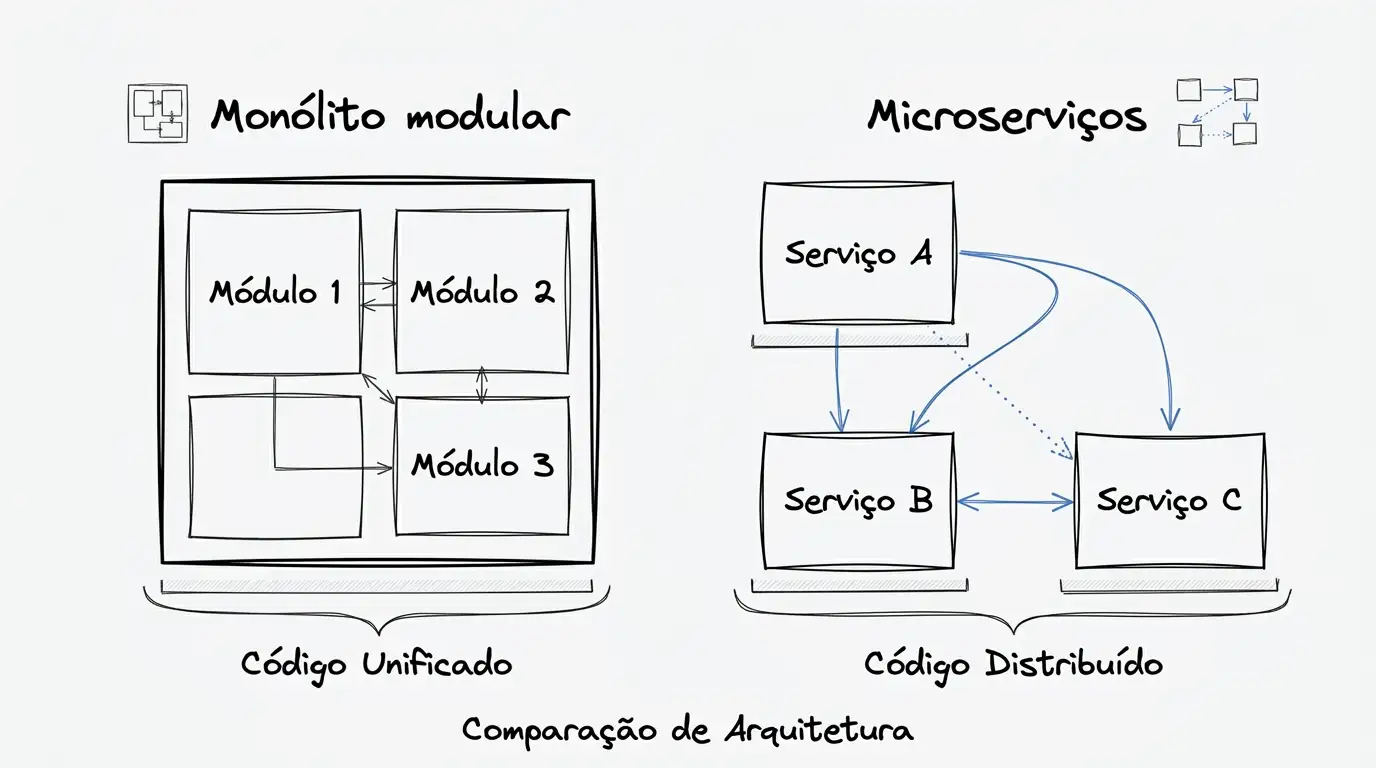
Monólito modular não é gambiarra temporária.
Em muitos cenários, ele é a escolha mais madura para começar — e às vezes para permanecer por muito tempo.
Separar serviço sem domínio claro só distribui o problema.
Você não reduz complexidade: só espalha acoplamento, contrato quebradiço e custo operacional em mais lugares.
Microserviços fazem sentido quando existe necessidade real, como:
domínios com autonomia clara
necessidade de escalabilidade muito desigual
times grandes demais para dividir o mesmo código sem atrito constante
exigências operacionais que pedem isolamento
Mesmo assim, o preço é alto.
Boa parte da complexidade dos sistemas distribuídos não está em “subir serviço”.
Ela está em conviver com falha parcial, fluxo assíncrono, observabilidade difícil e sem transformar o domínio em confusão.
Por isso, a pergunta certa não é “microserviços ou monólito?”.
É: o meu contexto já exige essa separação ou eu só estou antecipando problema?
Nem tudo precisa ser síncrono.
Em muitos cenários, insistir em resposta imediata aumenta custo, pressiona infraestrutura e complica operação sem gerar valor proporcional.
Em software enterprise, “tempo real” quase sempre precisa ser negociado com o negócio.
Às vezes o que parece requisito técnico é só expectativa mal alinhada.
Há casos em que a melhor decisão não é entregar tudo na hora, mas entregar com previsibilidade:
processar em segundo plano
assumir atraso controlado
responder depois com SLA claro
desacoplar etapas pesadas do fluxo principal
Exemplo clássico: um relatório pesado.
Ele realmente precisa ser gerado e baixado de forma síncrona na interface, bloqueando o usuário e pressionando o sistema? Em muitos casos, a melhor experiência é assíncrona: você dispara a geração, notifica quando terminar e entrega por e-mail com rastreabilidade.
No fim, arquitetura enterprise quase nunca é sobre “a solução mais bonita”.
É sobre a solução que continua fazendo sentido quando o sistema cresce, integra e começa a carregar consequência real.
Software enterprise não é “software maior”, nem “software com stack do momento”.
É software que passa a operar sob restrição real de negócio — com impacto em operação, integração, risco, governança e continuidade.
A virada acontece quando falha técnica deixa de ser detalhe de engenharia e vira problema de negócio.
Quando isso acontece, velocidade sozinha já não basta. O jogo muda: previsibilidade, observabilidade, segurança, contratos claros e capacidade de evoluir sem quebrar passam a importar tanto quanto entregar feature.
No fim, a pergunta mais importante não é “qual arquitetura parece mais moderna?”.
É outra: qual estrutura sustenta o sistema que eu tenho hoje sem atrapalhar o sistema que ele vai precisar virar amanhã?
O ponto é simples: pensar software enterprise não é pensar em hype. É pensar no que acontece quando o sistema deixa de ser só código e passa a sustentar trabalho real.
Se você for revisar seu sistema amanhã, começa por aqui:
Há clareza de contratos e versionamento nas integrações críticas?
Existe observabilidade que detecta falha antes de cliente reclamar?
O fluxo principal continua útil quando uma dependência externa cai?
As decisões de arquitetura foram tomadas por contexto real ou por hype?
Em software enterprise, o que parece ganho rápido hoje pode virar custo alto quando a operação pesa.