Nem todo bug é incidente — e nem todo incidente é bug
Bug e incidente não são sinônimos. Entenda a diferença entre defeito técnico e impacto operacional, e veja por que o mesmo problema pode virar backlog ou exigir resposta urgente em produção.
Engenheiro de Software focado em arquitetura e performance. Trabalho com Java/Spring Boot, SQL bem estruturado, serviços escaláveis na AWS e soluções GenAI com RAG (LangChain + bases vetoriais). Valorizo código legível e decisões bem justificadas.
É comum ver bug e incidente sendo tratados como sinônimos. Quando algo quebra em produção, muita gente resume tudo a “deu bug” — só que essa simplificação esconde uma diferença importante: ela mistura a falha técnica com o impacto real gerado em operação.
Bug e incidente podem estar ligados, mas não são a mesma coisa. Bug é o defeito no software. Incidente é a degradação, interrupção ou comportamento anormal que afeta usuários, serviço ou negócio e exige resposta. Um fala da causa técnica, já o outro, do impacto operacional.
Bug fala sobre defeito técnico; incidente fala sobre impacto e resposta.
Parece detalhe de vocabulário, mas não é. Confundir os dois bagunça prioridade, comunicação e tomada de decisão. O que poderia ser tratado como correção normal pode exigir contenção imediata, e o que deveria virar backlog às vezes é tratado como crise.
De forma objetiva, bug é um defeito no software capaz de impedir que um componente ou sistema cumpra sua função esperada. Em outras palavras: existe uma imperfeição real introduzida no sistema que compromete o comportamento esperado.
Esse ponto importa porque bug não é a mesma coisa que erro humano, nem a mesma coisa que falha observada em produção. O erro é a ação incorreta de quem especifica, implementa ou configura. O bug é o defeito que fica no software. Já a falha é a manifestação visível desse defeito quando ele aparece durante a execução do sistema.
Na prática, um bug pode aparecer de várias formas, por exemplo:
regra de negócio implementada errado
validação ausente ou incompleta
cálculo incorreto
consulta ineficiente
tratamento ruim de
integração quebrada
comportamento inesperado da interface
Em todos esses casos, a ideia central é a mesma: existe um defeito no sistema que compromete o comportamento esperado.
Cuidado importante
Nem todo bug se manifesta o tempo todo. Alguns ficam escondidos e só aparecem quando certas condições se combinam, como carga, dados específicos, ordem de execução ou ambiente.
Por isso, a existência de um bug não significa automaticamente que já exista um incidente. Nem todo bug causa impacto operacional — mas ele pode, sim, acabar causando um.
De forma objetiva, incidente é uma interrupção não planejada de um serviço, ou uma redução relevante na qualidade desse serviço, que exige resposta para restaurar a operação normal. O foco aqui não está na causa técnica em si, mas no impacto real gerado em produção.
Esse ponto importa porque incidente não é sinônimo de bug. Um bug pode estar presente no sistema sem gerar impacto imediato. Já o incidente aparece quando há degradação, indisponibilidade, erro operacional ou qualquer outro comportamento que afete usuários, serviço ou negócio e exija contenção, mitigação ou restauração.
Na prática, um incidente pode surgir de várias origens, por exemplo:
bug em produção
falha de infraestrutura
configuração incorreta
dependência externa indisponível
problema de rede
erro em deploy
degradação severa de performance
Em todos esses casos, a ideia central é a mesma: existe um problema em operação que precisa ser tratado com urgência compatível com seu impacto.
Mudança de perspectiva
Quando o problema afeta disponibilidade, qualidade, experiência do usuário ou operação do negócio, a conversa deixa de ser apenas “o que está quebrado no código” e passa a ser “o que está acontecendo com o serviço”.
Na prática, o problema entra no terreno do incidente quando começa a afetar usuários, serviço, operação, ou negócio e exige algum nível de resposta coordenada para conter impacto e restaurar a normalidade.
Antes de avançar, vale separar alguns termos que costumam aparecer nessa mesma conversa. Eles são relacionados, mas não significam a mesma coisa.
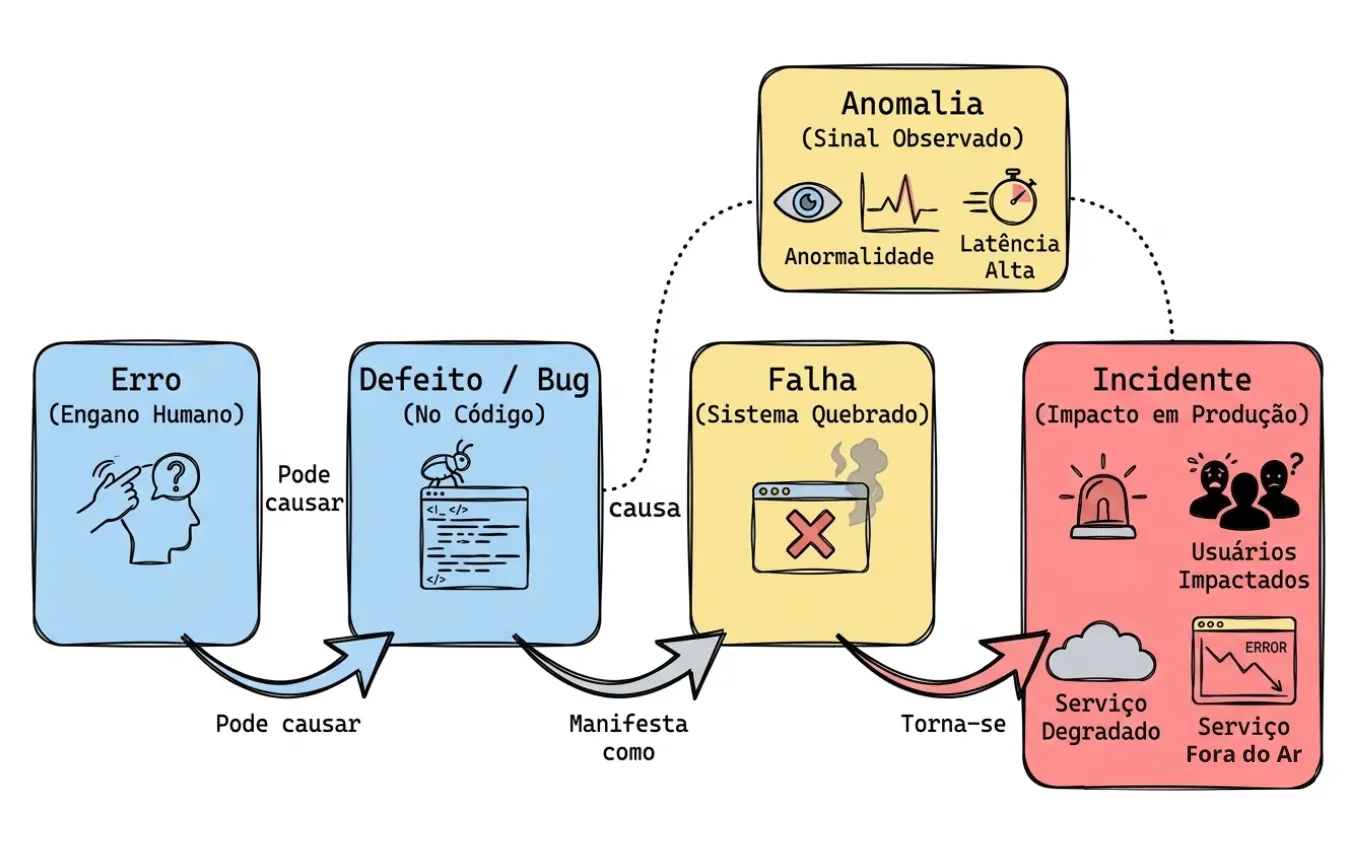
A imagem acima mostra a progressão mais comum de um problema em software. Tudo começa com um erro, ou seja, uma ação humana incorreta. Esse erro pode introduzir um defeito no código, na configuração ou até em outro artefato do sistema. Quando esse defeito se manifesta durante a execução, ele aparece como falha. Já a anomalia funciona como o sinal de que algo saiu do normal — seja por meio de logs, métricas, monitoramento ou percepção de usuários e times internos. Se esse problema passa a afetar serviço, operação ou negócio, aí entramos no terreno do incidente.
A tabela abaixo resume esses termos como referência rápida:
Termo
Onde mora
O que significa
Exemplo rápido
Erro
origem do problema
ação humana incorreta na especificação, implementação, configuração ou uso
usar operador errado, interpretar regra errada
Defeito
artefato de software
imperfeição introduzida em código, requisito, documentação ou configuração
lógica inválida, validação incompleta
Falha
execução do sistema
manifestação visível do problema quando o sistema se comporta fora do esperado
Imagine uma plataforma enterprise usada por grandes clientes para registrar pedidos, reservar estoque e emitir faturamento. Em uma terça-feira de manhã, o time faz deploy de uma alteração para melhorar a performance da reserva de itens no carrinho.
um cliente abre chamado dizendo que o estoque exibido no sistema não bate com a realidade
pouco depois, o suporte percebe que outros clientes também estão vendo inconsistências
em seguida, o time de operação identifica pedidos travados
a separação no centro de distribuição começa a duplicar
estoque, faturamento e expedição passam a divergir
Nesse ponto, o problema deixa de ser apenas uma falha técnica escondida no código. Ele já está afetando a operação real, a confiança no sistema e a capacidade de clientes continuarem trabalhando normalmente.
Lendo o cenário com clareza
erro: a decisão incorreta ou a implementação errada feita durante a alteração
defeito / bug: a lógica de concorrência que permitiu reserva duplicada
falha: o sistema reservando itens de forma incorreta durante a execução
anomalia: o aumento incomum de inconsistências, chamados e divergências operacionais
incidente: o impacto real em produção, afetando clientes, operação e fluxo de negócio
Perceba o ponto principal: o bug não “virou” outra coisa. Ele continuou sendo um bug. O que aconteceu foi que esse bug passou a causar um incidente, porque seu efeito saiu do nível técnico e passou a comprometer o serviço em operação.
Em um sistema pequeno, talvez esse problema fosse percebido mais tarde e tratado como correção normal de backlog. Em um ambiente enterprise, com múltiplos clientes, integrações e processos críticos dependendo do mesmo fluxo, o impacto escala rápido.
E quando isso escala rápido, a resposta já não pode ser só técnica — ela precisa ser operacional, porque o impacto vai muito além do código.
Times maduros não tratam bug e incidente como sinônimos, porque sabem que cada um exige uma resposta diferente.
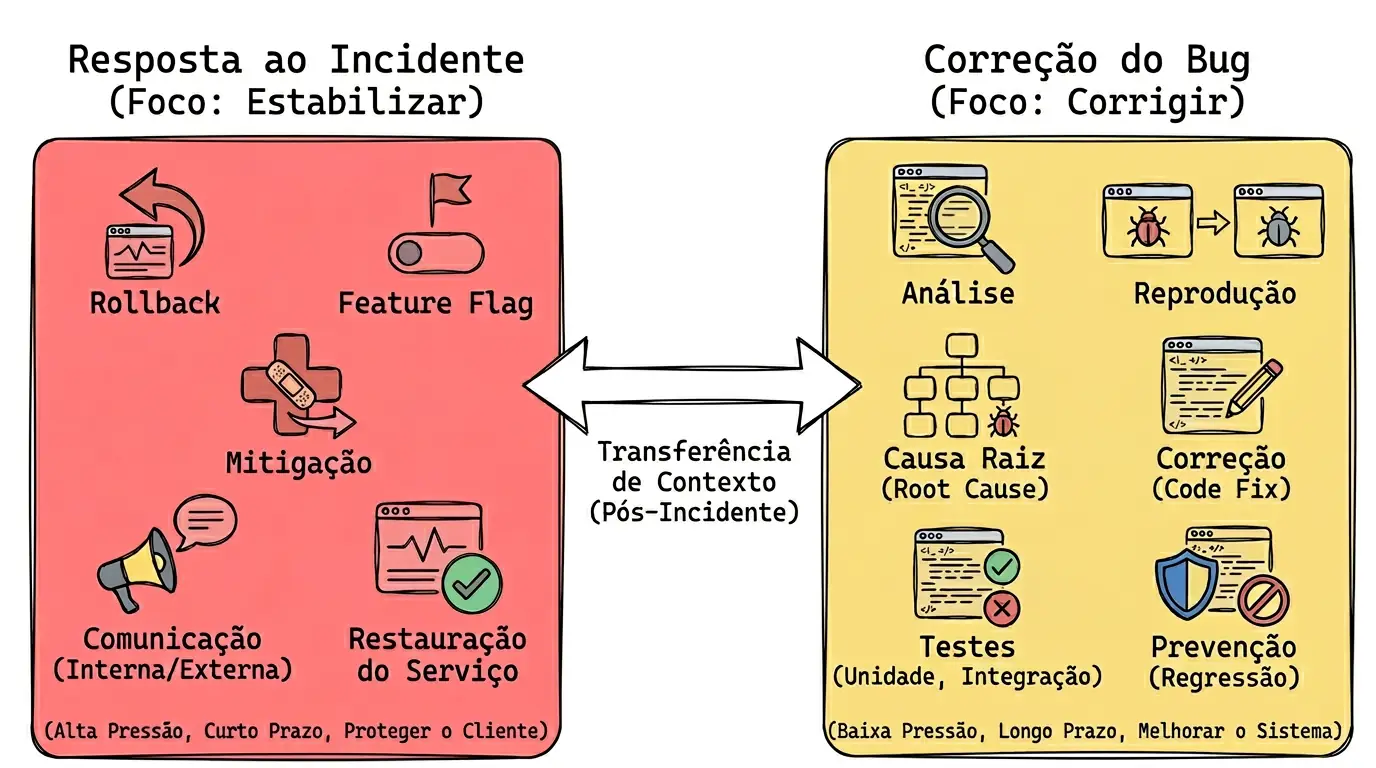
Quando há impacto real em produção, a prioridade deixa de ser simplesmente “corrigir o código” e passa a ser restaurar a operação com segurança. Nesse momento, o foco está em conter o problema, reduzir dano, comunicar o que está acontecendo e devolver estabilidade ao serviço no menor tempo possível.
Perceba que nenhuma dessas ações, necessariamente, corrige a causa raiz. Elas existem para controlar o impacto do incidente.
A correção definitiva vem depois. Aí, sim, entra o tratamento do bug: análise técnica, reprodução do problema, identificação da causa raiz, ajuste no código, testes, validação e prevenção para evitar recorrência.
Por isso, em times mais maduros, é comum que bug e incidente coexistam como registros diferentes. O incidente documenta impacto, severidade, linha do tempo, mitigação e comunicação. O bug registra o defeito técnico que precisa ser corrigido de forma definitiva.
Regra prática
Primeiro, estabilizar o serviço.
Depois, corrigir a falha com profundidade.
Por fim, aprender com o ocorrido para reduzir recorrência.
Essa separação evita dois erros comuns. O primeiro é tratar incidente como se fosse apenas uma tarefa de desenvolvimento, atrasando contenção e resposta. O segundo é tratar qualquer bug como crise operacional, gerando ruído, desgaste e priorização errada.
Nossos clientes não querem saber por que o serviço caiu; eles querem que ele volte a funcionar o mais rápido possível.
Gerenciar um incidente não é só procurar a linha de código errada. Na prática, é coordenar a resposta para reduzir impacto, restaurar o serviço e manter o time operando sem caos. As referências mais sólidas de incident management tratam isso como um processo que envolve detecção, triagem, mitigação, resolução, comunicação e aprendizado posterior.
Na prática, isso costuma envolver:
identificar o incidente e avaliar severidade, impacto e raio de alcance
definir papéis claros para evitar confusão durante a resposta
centralizar a comunicação em canais conhecidos e rastreáveis
conter o problema antes que ele se espalhe
mitigar ou restaurar o serviço com segurança o mais rápido possível
registrar a linha do tempo, decisões e mudanças realizadas
investigar a causa raiz depois da estabilização
transformar o que aconteceu em melhoria real para evitar recorrência
A ideia aqui é simples: primeiro vem a resposta operacional; depois, a correção definitiva da causa.
Em incidente, a pergunta principal não é só “qual é o bug?”, mas também:
“quem está sendo afetado, como reduzimos o impacto agora e como restauramos o serviço com segurança?”
Em outras palavras, gerenciar um incidente exige pelo menos quatro coisas funcionando juntas:
papéis claros, para evitar ruído e acelerar decisão
contenção e mitigação, para limitar impacto e restaurar o serviço
comunicação, para manter times e stakeholders alinhados
aprendizado, para reduzir a chance de recorrência
Isso é o que separa uma simples correção técnica de uma resposta operacional de verdade.
Nem todo incidente exige a mesma mobilização. Por isso, muitos times classificam incidentes por severidade e/ou prioridade, usando convenções como SEV1/SEV2/SEV3 ou P0/P1/P2, dependendo do modelo adotado.
De forma geral:
severidade ajuda a medir o impacto do incidente
prioridade ajuda a definir a urgência e a ordem de atuação
Na prática, isso evita tratar tudo como crise — e também evita subestimar incidentes que realmente exigem resposta rápida.
Bug e incidente até podem estar ligados, mas não são a mesma coisa. Bug fala sobre o defeito técnico. Incidente fala sobre o impacto operacional.
Essa diferença parece simples, mas muda bastante coisa na prática. Ela influencia como o time prioriza, comunica, mitiga, corrige e aprende com o problema. Quando esses conceitos se misturam, a resposta tende a piorar: bugs viram crises desnecessárias, e incidentes reais correm o risco de ser tratados como tarefas comuns de backlog.
No fim, a lógica é esta: erro pode introduzir um defeito, o defeito pode causar uma falha, e a falha pode evoluir para um incidente quando afeta usuários, serviço ou negócio. Entender essa cadeia ajuda times a responder melhor, com mais clareza e menos ruído.
Se seu time mistura defeito com impacto, ele não só nomeia mal o problema — ele também responde pior a ele.