Enterprise Software: what changes when the product needs to operate as a platform
Scale, availability, compliance, and integration stop being “extras” and become survival requirements. A practical guide to the trade-offs and decisions that separate a common system from an enterprise platform.
software
architecture
enterprise
platform
Ednaldo Luiz
Level: Intermediate
Level:
Published:
Last updated:
Recommended
Related content about enterprise software and enterprise architecture.
Software Engineer focused on architecture and performance. I work with Java/Spring Boot, well-structured SQL, scalable services on AWS, and GenAI solutions with RAG (LangChain + vector databases). I value readable code and well-justified decisions.
When a product becomes a platform, it stops serving just one team and starts supporting multiple consumers at the same time: internal departments, integrations, automations, partners, and even other products.
Every SaaS company wants to reach that point. But this is where the game changes: decisions that were “good enough” when the focus was shipping fast start charging interest in operations, cost, and risk.
Shipping features fast is not the problem. That is normal — and often necessary — for growth. The problem starts when technical debt stops being an annoyance and becomes real business risk: a small incident starts affecting revenue, support, compliance, or someone else’s day-to-day operation.
From that point on, the question is no longer “how do we ship faster?”.
It becomes something else: how do we operate without breaking, while keeping cost, risk, and evolution under control.
And one important point: there is no universal formal definition of “enterprise software.” It is not a technical badge. It is a context — a type of environment where the constraints are real and force different decisions.
As I often say, there is no formal definition for this term.
The goal of this article is to organize what people usually call enterprise software in practice and show why choices that once looked small start getting expensive when the product stops being just software and starts supporting real work.
Before talking about enterprise software, it is worth aligning on the basics: what a product is.
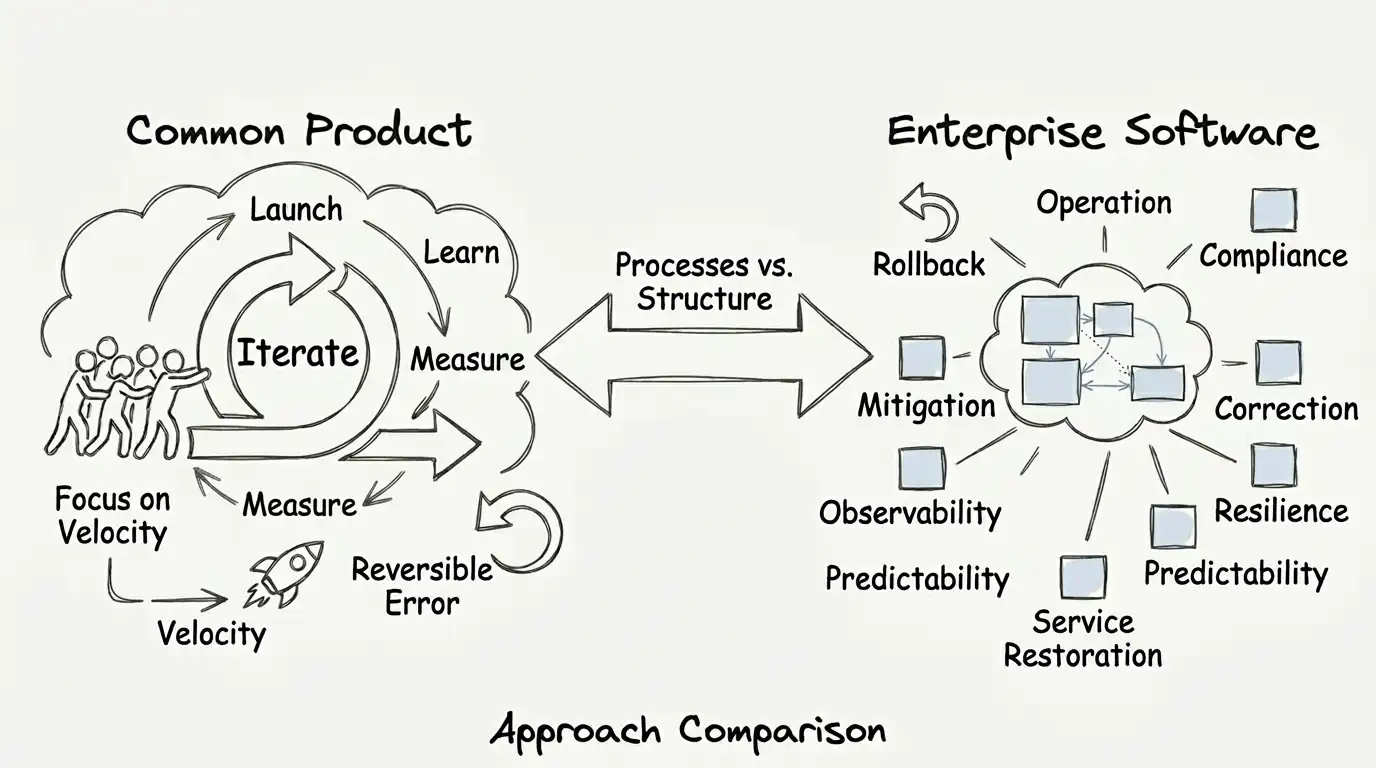
In practice, a product is a solution created to deliver value fast and improve through real usage. The loop is simple: launch → measure → fix → repeat. At that stage, making mistakes is tolerable because the impact tends to be contained — you can revert, fix, and move on.
Enterprise software appears when that same product becomes a work foundation. It starts supporting operations, contracts, integrations, and business decisions.
That is when the game changes: you optimize for predictability — controlled risk, reliable integration, security, and steady evolution. Because here, an error does not become “just a bug.” It becomes an incident.
If you want to explore that distinction further, check out our article on .
The core difference is not system size. It is how much the operation, the customer, and the business depend on it to function.
One important clarification: not every large product becomes enterprise software, and enterprise software is not limited to banks, hospitals, or governments.
In the end, what pushes software into enterprise territory is not size. It is the level of dependency, risk, and consequence it starts to carry.
This also helps separate two things people often mix up: category and context.
A system may be born in a domain that often becomes enterprise — such as legal, healthcare, or finance — and still, at an early stage, not carry that full weight.
Likewise, a huge product does not become enterprise just because it grew. Without critical operations, sensitive integrations, and real business consequence, size alone is not enough.
So the practical question is not “what stack should I use?” or “how many users do I have?”.
It is another one: at what point does this system stop being just a product and start holding day-to-day operations?
You know it has become “enterprise” when a small bug stops being “just annoying” and turns into a domino effect:
it affects revenue (payments, subscriptions, billing)
it breaks operations (queues stall, internal teams can no longer work)
it becomes a support incident (support gets flooded, gets breached)
it touches compliance (audit, GDPR, access trails)
or it creates reputational risk (a major customer demanding explanations)
From that point on, “it works on my machine” stops being acceptable for a simple reason: the real environment is production — with real data, real load, real integrations, and real people depending on it.
If it runs on your machine but fails in the real world, that means almost nothing. Customers, support, operations, leadership, and the people accountable for the business do not care that “it worked here.” What matters is something else: does it work in production, with predictability, controlled risk, and no surprises.
The focus changes:
before: ship more
after: ship with reliability
and above all: do not break what is already standing
If you remember one thing up to this point, let it be this: enterprise is not size — it is consequence.
Once the system starts supporting real operations, the way decisions are made changes.
Technical decisions stop being only implementation choices and also become choices about risk, cost, and continuity.
That is why some priorities move to the top:
Contracts and compatibility
APIs, events, and integrations stop being internal details. You need to think about versioning, , and change impact before publishing anything.
Observability
Without useful logs, metrics, alerts, and , you are not operating — you are guessing. And a critical system cannot depend on guesswork.
Security by default
Consistent authorization, audit trails, and least privilege stop being “refinement.” They become a basic requirement to reduce exposure and answer for access, actions, and data.
Resilience
Timeouts, retries with criteria, , and controlled degradation start to matter because external dependencies fail, queues lag, and networks fluctuate. The system must remain useful even when something around it breaks.
Delivery process
CI/CD, trustworthy tests, , and safe migrations stop being luxuries for organized teams. They are what prevent deployments from becoming incidents.
And that is exactly where the next question comes in: what supports this kind of software in daily life?
Enterprise software is not sustained by pretty architecture or a modern stack alone.
Your favorite JS framework is not what will save operations when the system becomes a platform.
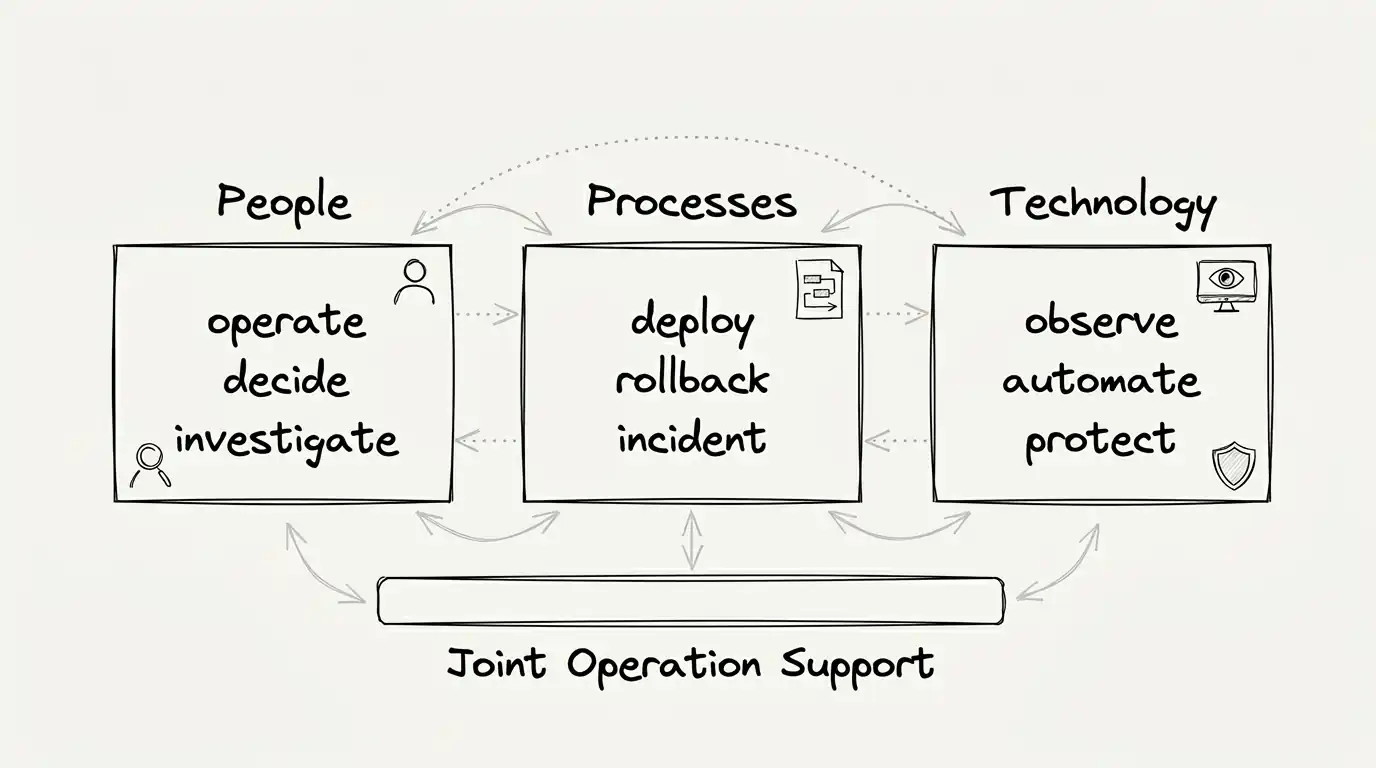
In practice, it rests on three pillars that need to work together: people, processes, and technology.
If one fails, the system loses predictability.
If two fail, operations turn into improvisation.
If all three fail at the same time, the problem is no longer technical — it is organizational.
People operate, investigate, decide, and step up when something leaves the normal path.
Without people who understand the domain, the critical flows, and the system risks, any incident turns into chaos.
Processes exist to make the team act in a predictable and safe way, without improvising all the time.
Deployments, rollbacks, incident management, change review, production access, and failure response cannot depend on memory or goodwill.
Technology is there to sustain all of that well: observing, automating, protecting, integrating, and recovering.
But tools alone do not sustain operations. Enterprise software holds up when prepared people, clear processes, and useful technology work in the same direction.
To some people, governance means bureaucracy.
In practice, it is what creates the minimum alignment needed so autonomy does not become disorder and speed does not become risk.
Governance is what defines boundaries, responsibilities, and minimum standards before complexity gets out of control.
Governance answers questions enterprise teams cannot leave hanging:
who can change what
who approves critical changes
how to version a contract without breaking consumers
how to handle incidents, exceptions, and sensitive access
which standards are mandatory and which are only recommendations
Without that, the system may still grow — but it grows out of alignment:
each team decides in its own way
each module is born with the stack the team prefers, without looking at the ecosystem
each integration creates its own rule — and what could exist as one reliable point ends up being rebuilt in several places
each incident turns into a discussion about — and sometimes about blame
At first, that looks like autonomy.
Over time, it becomes friction, inconsistency, and an operation much more fragile than it should be.
And when those pillars do not hold up well, operational requirements start driving the game.
Scalability is not just about handling more load.
It is about growing without destroying latency, cost, or operations in the process.
In enterprise software, this matters because the system almost never grows alone: it grows together with integrations, data, consumers, usage spikes, and new dependencies.
Scaling well is not just about adding more machines.
It is about continuing to respond predictably as the context becomes larger and heavier.
Scaling poorly is not just about losing performance.
Sometimes it means turning growth into cost, friction, and painful operations.
A system being online does not impress anyone when the function that matters is still failing.
Availability is not just about servers being up.
Real availability means the right functionality is accessible when the business needs it.
If login works but the main module does not, then for the user the system is unavailable.
In enterprise, availability is perceived by operations, not by the infra dashboard.
Security here is not an implementation detail.
It is access control, audit trails, data protection, and the ability to answer who did what.
Compliance comes in the same package: in many contexts, it is not enough to work.
It has to work the right way, with traceability, clear rules, and defined accountability.
When the system supports real operations, security stops being an “extra layer.”
It becomes part of the business operating contract.
In enterprise, integration is not a detail.
It is what naturally happens as the system grows.
The system has to talk to legacy platforms, partners, vendors, , , , and internal flows.
The question is never “will it integrate?”.
It is how to integrate without spreading coupling, duplicated logic, and fragility along the way.
Another critical point is not attaching business rules to a specific provider’s API.
When that happens, switching vendors becomes almost like rewriting a critical flow. The ideal is to isolate integrations through clear contracts and adapters, keeping the domain stable even when the partner changes.
If you cannot see the system, you are not operating the system.
You are reacting in the dark.
Logs, metrics, alerts, and tracing are what let you understand behavior, investigate failures, and respond quickly.
In enterprise environments, black boxes are operational risk.
If you cannot see what is happening, you cannot decide well or fix fast.
And there is a common mistake here: assuming that no complaints means no problem. Many failures go unreported, or are not even noticed by the customer, and stay hidden until they become bigger incidents.
Enterprise almost always demands two things at the same time: standardization to operate well and flexibility to address different realities.
If you standardize everything, you block the business.
If you adapt everything without criteria, you destroy maintainability.
This also applies to the decision between building and relying on third parties.
Not everything makes sense to build from scratch — but outsourcing too much can cost control, speed, and differentiation.
The healthy middle ground is this: standardize what needs to be common, adapt what truly differentiates, and modularize the system so that variation does not turn into disorder.
Without clear limits, what used to be an exception becomes the rule — and maintenance degrades.
In enterprise software, the application is rarely the only critical thing.
Many times, the most valuable asset is the data it carries, preserves, and moves around.
That is why evolving the system is not just about changing code.
It is also about protecting integrity, history, compatibility, and migration without turning the data layer into operational risk.
Changing a business rule in code is usually fast.
The hard part is making sure old data still makes sense after the change.
When this breaks, it usually does not break visibly in code first.
It breaks in history, integration behavior, and trust in what the system knows.
When that care is missing, the problem shows up quickly:
the rule changes, but old data remains in the previous format
a new integration interprets the information differently
history stops matching the present
migration becomes a gamble
audit finds the data, but no one can explain its path
In enterprise, data is not just storage.
It is operational memory, a contract between systems, and evidence of what has already happened.
When data becomes a critical asset, every technical decision becomes more expensive to undo.
And that is when trade-offs stop being theory.
When software fully enters enterprise territory, architecture stops being only code organization.
It also becomes a way to control risk, preserve operations, and support evolution without collapsing what already works.
In practice, this changes three decisions all the time: how simple you can remain, when separation is worth it, and what really needs to happen in real time.
Simplicity almost always wins in the beginning.
It reduces friction, speeds up delivery, and makes the system easier to understand, operate, and fix.
The mistake is confusing simplicity with naivety.
Architecture that is too simple, without looking at growth, integration, and real load, may break early when the system starts supporting real operations.
On the other side, scaling too early is also expensive.
Too many layers, too many services, and too much abstraction slow delivery and put complexity where no real problem exists yet.
The healthy point is simple: start with the simplest solution that supports the current context, but do not close the doors to evolution.
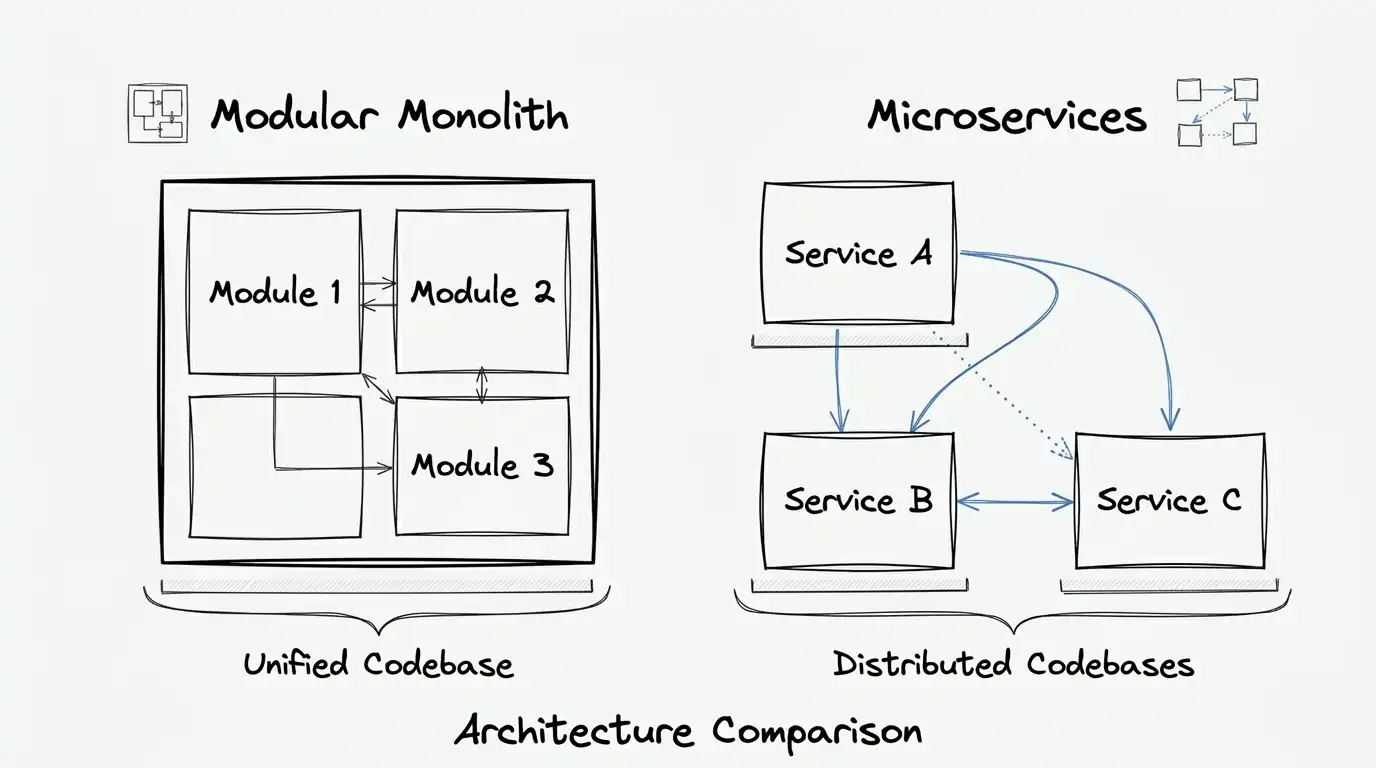
A modular monolith is not a temporary hack.
In many scenarios, it is the most mature choice to start with — and sometimes to stay with for a long time.
Splitting services without a clear domain only distributes the problem.
You do not reduce complexity: you just spread coupling, fragile contracts, and operational cost across more places.
Microservices make sense when there is real need, such as:
domains with clear autonomy
very uneven scalability needs
teams too large to share the same codebase without constant friction
operational requirements that demand isolation
Even then, the price is high.
A big part of distributed systems complexity is not in “starting services.”
It is in living with partial failure, asynchronous flow, difficult observability, and without turning the domain into confusion.
So the right question is not “microservices or monolith?”.
It is: does my context already require that separation, or am I just anticipating a problem?
Not everything needs to be synchronous.
In many scenarios, insisting on immediate response increases cost, puts pressure on infrastructure, and complicates operations without generating proportional value.
In enterprise software, “real time” almost always needs to be negotiated with the business.
Sometimes what looks like a technical requirement is just a poorly aligned expectation.
There are cases where the best decision is not to deliver everything immediately, but to deliver with predictability:
process in the background
accept controlled delay
respond later with a clear SLA
decouple heavier stages from the main flow
A classic example: a heavy report.
Does it really need to be generated and downloaded synchronously in the interface, blocking the user and pressuring the system? In many cases, the best experience is asynchronous: you trigger the generation, notify when it is done, and deliver it by email with traceability.
In the end, enterprise architecture is almost never about “the prettiest solution.”
It is about the solution that keeps making sense when the system grows, integrates, and starts carrying real consequence.
Enterprise software is not “bigger software,” nor “software with the trendy stack.”
It is software that starts operating under real business constraints — with impact on operations, integration, risk, governance, and continuity.
The turning point happens when technical failure stops being an engineering detail and becomes a business problem.
Once that happens, speed alone is no longer enough. The game changes: predictability, observability, security, clear contracts, and the ability to evolve without breaking things start to matter just as much as shipping features.
In the end, the most important question is not “which architecture looks more modern?”.
It is another one: which structure sustains the system I have today without getting in the way of the system it will need to become tomorrow?
The point is simple: thinking about enterprise software is not thinking about hype. It is thinking about what happens when the system stops being just code and starts supporting real work.
If you are going to review your system tomorrow, start here:
Are contracts and versioning clear in critical integrations?
Is there observability that detects failure before the customer complains?
Does the main flow remain useful when an external dependency fails?
Were architecture decisions made based on real context or on hype?
In enterprise software, what looks like a quick win today can become a high cost when operations start to weigh in.