Not every bug is an incident — and not every incident is a bug
Bugs and incidents are not synonyms. Understand the difference between technical defect and operational impact, and see why the same problem can end up in the backlog or require an urgent production response.
Software Engineer focused on architecture and performance. I work with Java/Spring Boot, well-structured SQL, scalable services on AWS, and GenAI solutions with RAG (LangChain + vector databases). I value readable code and well-justified decisions.
It is common to see bugs and incidents treated as synonyms. When something breaks in production, many people reduce everything to “it’s a bug” — but that simplification hides an important difference: it mixes technical failure with the real impact generated in operations.
Bugs and incidents may be related, but they are not the same thing. A bug is the defect in the software. An incident is the degradation, interruption, or abnormal behavior that affects users, service, or business and requires a response. One talks about the technical cause; the other talks about the operational impact.
A bug talks about technical defect; an incident talks about impact and response.
It may sound like a vocabulary detail, but it is not. Confusing the two messes up prioritization, communication, and decision-making. What could be treated as a normal fix may require immediate containment, while what should go to the backlog is sometimes treated like a crisis.
Objectively, a bug is a defect in the software that can prevent a component or system from performing its expected function. In other words, there is a real imperfection introduced into the system that compromises expected behavior.
This matters because a bug is not the same thing as human error, nor is it the same thing as a failure observed in production. An error is the incorrect action made by whoever specifies, implements, or configures something. A bug is the defect that remains in the software. A failure is the visible manifestation of that defect when it appears during system execution.
In practice, a bug can show up in several ways, for example:
a business rule implemented incorrectly
missing or incomplete validation
an incorrect calculation
an inefficient query
poor handling
a broken integration
unexpected interface behavior
In all these cases, the core idea is the same: there is a defect in the system that compromises expected behavior.
Important caution
Not every bug manifests all the time. Some remain hidden and only appear when certain conditions align, such as load, specific data, execution order, or environment.
That is why the existence of a bug does not automatically mean there is already an incident. Not every bug causes operational impact — but it may, in fact, end up causing one.
Objectively, an incident is an unplanned interruption of a service, or a relevant reduction in the quality of that service, which requires a response to restore normal operation. The focus here is not the technical cause itself, but the real impact generated in production.
This matters because an incident is not a synonym for bug. A bug may exist in the system without creating immediate impact. An incident appears when there is degradation, unavailability, operational error, or any other behavior that affects users, service, or business and requires containment, mitigation, or restoration.
In practice, an incident can arise from several sources, for example:
a bug in production
infrastructure failure
incorrect configuration
an unavailable external dependency
a network problem
a deployment error
severe performance degradation
In all these cases, the core idea is the same: there is an operational problem that needs to be handled with urgency proportional to its impact.
A shift in perspective
When the problem affects availability, quality, user experience, or business operations, the conversation stops being only about “what is broken in the code” and starts being about “what is happening to the service”.
In practice, the problem enters incident territory when it starts affecting users, service, operations, , or business and requires some level of coordinated response to contain impact and restore normality.
Before moving on, it is worth separating a few terms that usually show up in this same conversation. They are related, but they do not mean the same thing.
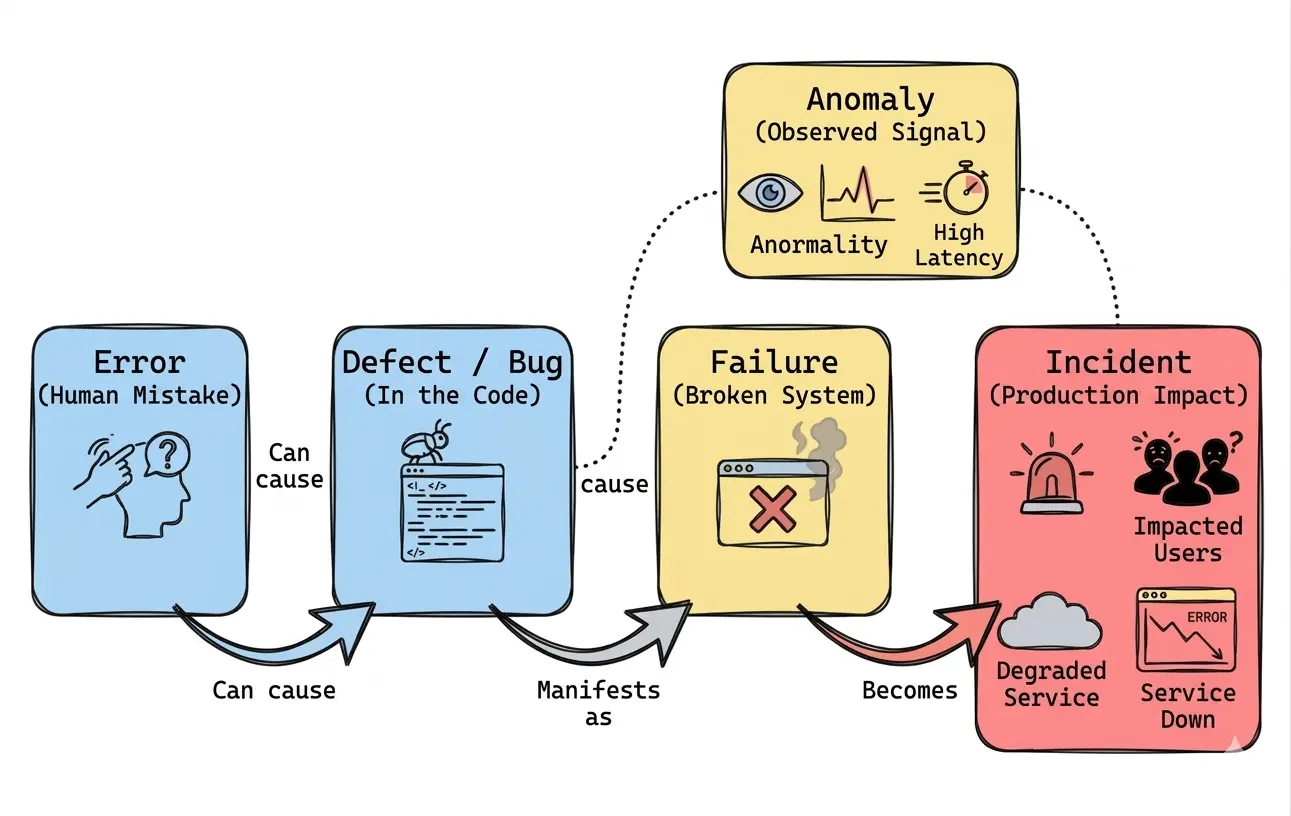
The image above shows the most common progression of a software problem. Everything starts with an error, meaning an incorrect human action. That error can introduce a defect in the code, configuration, or even another system artifact. When that defect manifests during execution, it appears as a failure. An anomaly, in turn, acts as the signal that something has gone off the normal path — whether through logs, metrics, monitoring, or the perception of users and internal teams. If that problem starts affecting service, operations, or business, then we enter the territory of an incident.
The table below summarizes these terms as a quick reference:
Term
Where it lives
What it means
Quick example
Error
source of the problem
incorrect human action in specification, implementation, configuration, or use
using the wrong operator, misinterpreting a rule
Defect
software artifact
imperfection introduced into code, requirement, documentation, or configuration
invalid logic, incomplete validation
Failure
system execution
visible manifestation of the problem when the system behaves outside the expected
Imagine an enterprise platform used by large customers to register orders, reserve stock, and generate billing. On a Tuesday morning, the team deploys a change to improve the performance of item reservation in the cart.
In the first few minutes, nothing seems out of the ordinary. The tests passed, the deployment finished without errors, and the main dashboards are still green.
But as traffic increases, something strange starts happening: some orders are reserving the same item more than once.
a customer opens a ticket saying the stock shown in the system does not match reality
shortly after, support notices that other customers are seeing inconsistencies too
then the operations team identifies stuck orders
picking in the distribution center starts being duplicated
stock, billing, and shipping begin to diverge
At this point, the problem stops being just a technical failure hidden in the code. It is already affecting real operations, trust in the system, and the ability of customers to keep working normally.
Reading the scenario clearly
error: the incorrect decision or wrong implementation made during the change
defect / bug: the concurrency logic that allowed duplicate reservations
failure: the system reserving stock incorrectly during execution
anomaly: the unusual increase in inconsistencies, tickets, and operational divergences
incident: the real production impact affecting customers, operations, and business flow
Notice the main point: the bug did not “turn into” something else. It remained a bug. What happened is that this bug started causing an incident, because its effect moved beyond the technical level and began compromising the service in operation.
In a small system, this problem might have been noticed later and treated as a normal backlog fix. In an enterprise environment, with multiple customers, integrations, and critical processes depending on the same flow, the impact scales quickly.
And when that scales quickly, the response can no longer be only technical — it must be operational, because the impact goes far beyond the code.
Mature teams do not treat bugs and incidents as synonyms, because they know each one requires a different response.
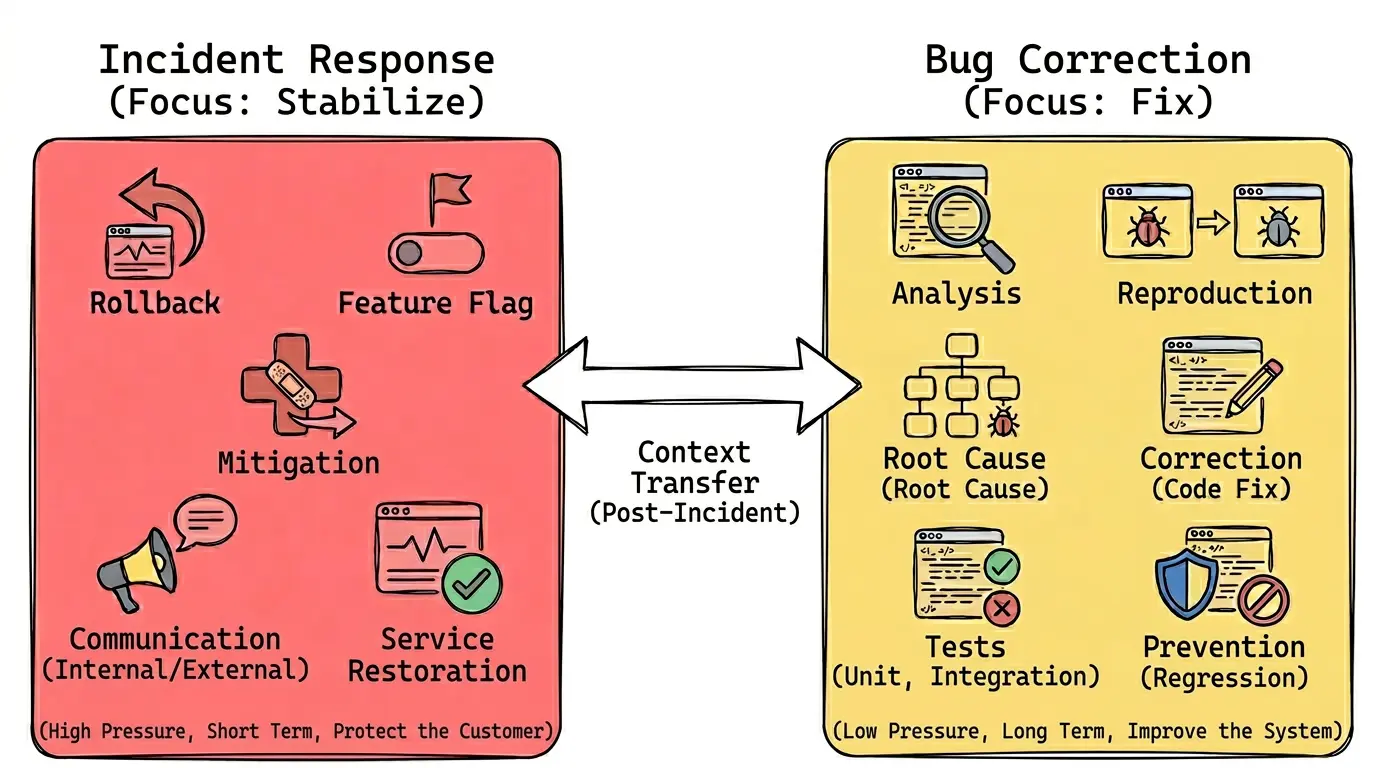
When there is real production impact, the priority stops being simply “fix the code” and becomes restore operations safely. At that moment, the focus is on containing the problem, reducing damage, communicating what is happening, and bringing stability back to the service as quickly as possible.
Notice that none of these actions necessarily fixes the root cause. They exist to control the impact of the incident.
The definitive fix comes later. That is when bug treatment enters: technical analysis, reproducing the problem, identifying the root cause, changing the code, testing, validation, and prevention to avoid recurrence.
That is why, in more mature teams, it is common for bug and incident to coexist as separate records. The incident documents impact, severity, timeline, mitigation, and communication. The bug records the technical defect that needs to be fixed definitively.
Practical rule
First, stabilize the service.
Then, fix the failure thoroughly.
Finally, learn from what happened to reduce recurrence.
This separation avoids two common mistakes. The first is treating an incident as if it were only a development task, delaying containment and response. The second is treating every bug like an operational crisis, generating noise, fatigue, and wrong prioritization.
Our customers don't care why their service is down, only that we restore service as quickly as possible.
Managing an incident is not just about looking for the wrong line of code. In practice, it is about coordinating the response to reduce impact, restore the service, and keep the team operating without chaos. The strongest incident management references treat this as a process involving detection, triage, mitigation, resolution, communication, and post-incident learning.
In practice, this usually includes:
identifying the incident and evaluating severity, impact, and blast radius
defining clear roles to avoid confusion during the response
centralizing communication in known and traceable channels
containing the problem before it spreads
mitigating or restoring the service safely as quickly as possible
recording the timeline, decisions, and changes made
investigating the root cause after stabilization
turning what happened into real improvement to prevent recurrence
The idea here is simple: operational response comes first; definitive correction of the cause comes after.
In an incident, the main question is not only “what is the bug?”, but also:
“who is being affected, how do we reduce the impact now, and how do we restore the service safely?”
In other words, managing an incident requires at least four things working together:
clear roles, to avoid noise and speed up decisions
containment and mitigation, to limit impact and restore the service
communication, to keep teams and stakeholders aligned
learning, to reduce the chance of recurrence
That is what separates a simple technical fix from a real operational response.
Not every incident requires the same level of mobilization. That is why many teams classify incidents by severity and/or priority, using conventions such as SEV1/SEV2/SEV3 or P0/P1/P2, depending on the model they adopt.
In general:
severity helps measure the impact of the incident
priority helps define urgency and order of response
In practice, this prevents treating everything like a crisis — and also prevents underestimating incidents that truly require a fast response.
Bugs and incidents may be related, but they are not the same thing. A bug talks about the technical defect. An incident talks about the operational impact.
That difference seems simple, but it changes a lot in practice. It influences how the team prioritizes, communicates, mitigates, fixes, and learns from the problem. When these concepts get mixed up, the response tends to get worse: bugs turn into unnecessary crises, and real incidents risk being treated like ordinary backlog tasks.
In the end, the logic is this: an error can introduce a defect, the defect can cause a failure, and the failure can evolve into an incident when it affects users, service, or business. Understanding this chain helps teams respond better, with more clarity and less noise.
If your team mixes up defect and impact, it does not just name the problem poorly — it also responds to it poorly.
Question1/5
What is the core difference between a bug and an incident?