Como estimar crescimento de storage com writes, replicação e retenção
Um guia prático para calcular storage a partir de writes por segundo, tamanho médio dos dados, fator de replicação e tempo de retenção antes que o volume vire custo ou gargalo em produção.
storage
capacity planning
systems design
software architecture
scalability
databases
Ednaldo Luiz
Nível: Intermediário
Nível:
Publicado:
Última atualização:
Recomendados
Conteúdos relacionados a estimativa de storage e capacity planning.
Engenheiro de Software focado em arquitetura e performance. Trabalho com Java/Spring Boot, SQL bem estruturado, serviços escaláveis na AWS e soluções GenAI com RAG (LangChain + bases vetoriais). Valorizo código legível e decisões bem justificadas.
Sabe quando está tudo tranquilo, até o mês em que a conta chega? O storage estourou o orçamento, e ninguém sabe explicar de onde vieram os últimos terabytes.
Storage quase nunca parece um problema no começo. Só que dado tem uma manha: ele acumula — um log aqui, um evento ali, todo santo dia.
O que parece pequeno por segundo pode virar dezenas de gigabytes por dia e vários terabytes por ano — ainda mais quando entram replicação, retenção, backup e histórico.
Por isso, estimar storage não é sobre fazer uma conta perfeita — é sobre enxergar a ordem de grandeza antes que o crescimento vire custo, gargalo ou incidente em produção. O objetivo é estar preparado para o crescimento, não acertar o número exato.
TL;DR
Estimar storage é montar a conta em camadas, cada uma multiplicando a anterior:
writes/s × tamanho médio = dados gerados por segundo
volume diário × tempo de retenção = storage lógico
storage lógico × fator de replicação = storage estimado
Ela não precisa ser exata — só boa o suficiente para mostrar a ordem de grandeza e evitar que crescimento, retenção e replicação virem surpresa em produção.
Antes de pensar em banco de dados, disco, , backup ou qualquer tecnologia específica, precisamos responder a uma pergunta mais básica: em que velocidade o sistema está produzindo dados?
Essa primeira conta depende de duas informações:
quantas gravações acontecem por segundo;
qual é o tamanho médio de cada gravação.
A partir delas, conseguimos calcular a taxa de geração de dados do sistema. Ainda não estamos considerando tempo de retenção, replicação, índices, backups ou estruturas internas do banco. Neste primeiro momento, queremos apenas entender quanto dado novo é produzido a cada segundo.
Não é a estimativa final, mas é o ponto de partida para todas as outras contas.
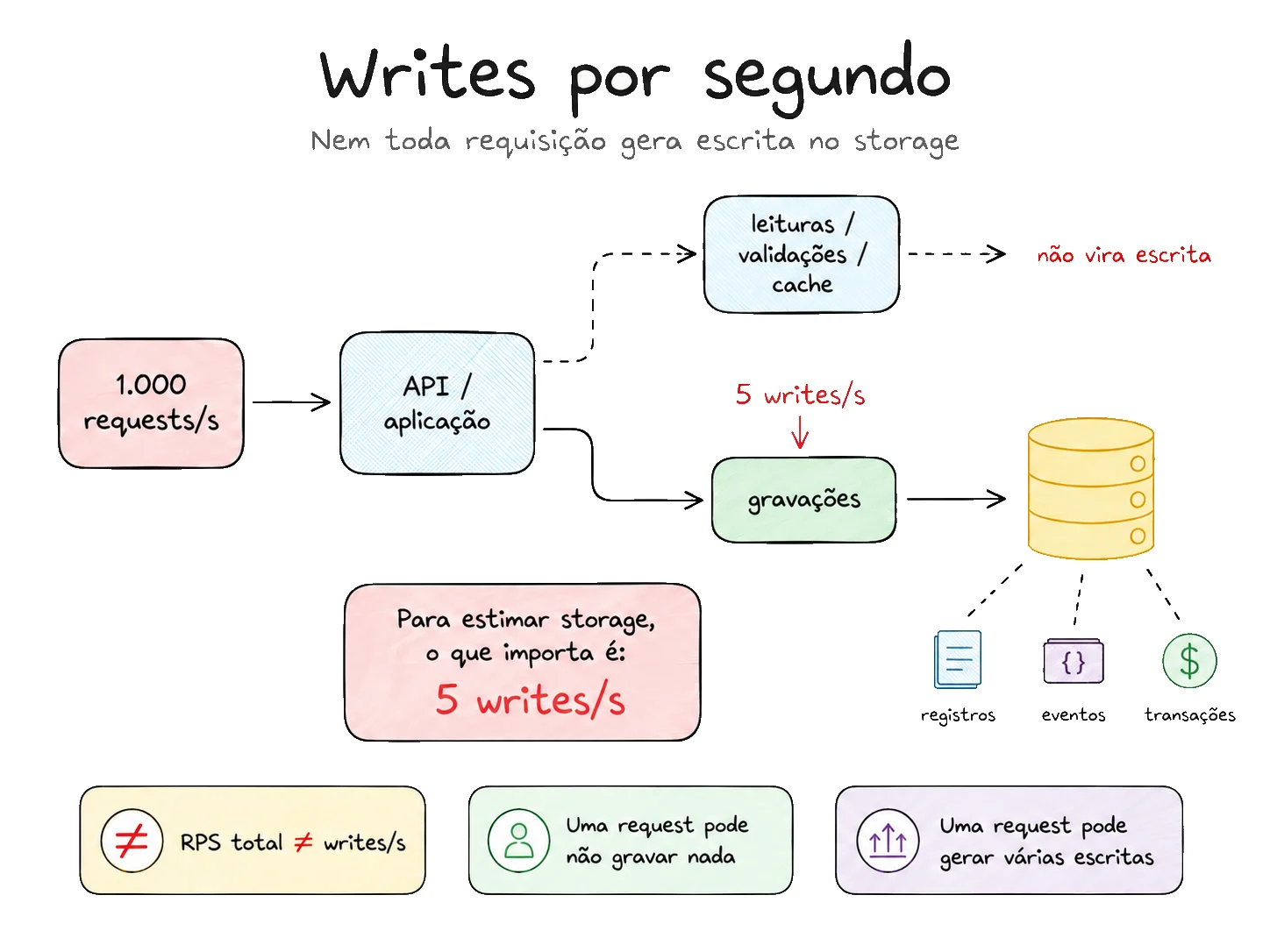
O primeiro passo é descobrir quantas operações realmente geram dados persistidos a cada segundo.
Aqui existe uma diferença importante entre e writes por segundo: não são a mesma coisa.
Um sistema pode receber 1.000 requisições por segundo, mas grande parte delas pode ser composta por leituras, validações, consultas em cache ou operações que não persistem nenhuma informação.
O contrário também pode acontecer. Uma única requisição pode gerar várias escritas. A criação de um pedido, por exemplo, pode gravar o pedido, seus itens, um evento de auditoria, uma mensagem em uma fila e um log estruturado.
Para estimar storage, o que importa é a quantidade de operações que realmente produzem dados que serão armazenados.
Na prática, esse writes/s vem de uma medição (métricas reais do sistema) ou de uma estimativa de tráfego — usuários ativos (DAU) → requisições → escritas. Mas a conta de tráfego é um exercício à parte; aqui partimos direto das gravações.
Suponha que o sistema realize:
Isso significa que cinco novos registros, eventos, transações ou documentos são produzidos a cada segundo.
Depois, precisamos entender quanto pesa cada gravação.
Esse valor pode variar bastante dependendo do tipo de dado. Um evento simples pode ter poucos kilobytes. Uma transação com mais informações pode ser maior. Um log estruturado pode crescer rápido. Já um arquivo, imagem ou documento muda completamente a escala da conta.
Para uma primeira estimativa, usamos um tamanho médio.
Por exemplo:
Esse número não precisa ser perfeito no começo. O objetivo é encontrar uma ordem de grandeza.
Também é importante lembrar: aqui estamos falando do dado lógico, ou seja, do tamanho aproximado da informação gravada. Ainda não entraram na conta índices, réplica, backup, , journal, snapshots ou qualquer overhead interno do storage.
Mesmo assim, essa estimativa já ajuda muito. É melhor trabalhar com um número aproximado do que ignorar o crescimento ou achar que o storage não é um problema, até que ele se torne um.
Com essas duas informações, a conta base fica assim:
Taxa de gravação
Tamanho médio
Geração de dados
writes por segundo
×
tamanho médio por gravação
=
dados gerados por segundo
Taxa de gravação
writes por segundo
×
Usando o exemplo:
Taxa de gravação
Tamanho médio
Geração de dados
5 writes/s
×
50 KB
=
250 KB/s
Taxa de gravação
5 writes/s
×
250 KB parece pouco. E, isoladamente, realmente é.
Mas estamos falando de apenas um segundo e de uma carga aparentemente pequena: cinco gravações de 50 KB. Quando esse mesmo ritmo continua durante o dia inteiro, todos os dias, o volume deixa de parecer tão inofensivo.
O problema do storage não costuma estar em uma gravação. Está no acúmulo.
Agora que temos a taxa de geração de dados, podemos colocar tempo nessa conta.
Agora que sabemos quanto dado o sistema produz por segundo, precisamos entender o que acontece quando esse ritmo continua durante horas, dias, meses ou anos.
É nesse momento que números aparentemente pequenos começam a crescer rápido — e também quando as contas ficam cheias de zeros, conversões e unidades diferentes.
Aproximações e notação científica ajudam justamente nisso: simplificam o cálculo sem esconder a escala real do problema. Em vez de buscar precisão absoluta desde o primeiro passo, conseguimos chegar rapidamente a uma estimativa útil e entender para onde o volume está caminhando.
Em uma estimativa inicial de capacidade, o objetivo é descobrir a ordem de grandeza do problema. Queremos saber se o sistema produzirá megabytes, gigabytes, terabytes ou petabytes. Nesse momento, chegar a um número perfeitamente exato costuma ser menos importante do que conseguir concluir a conta e entender sua escala.
Um dia possui exatamente 86.400 segundos. Para simplificar uma estimativa rápida, podemos arredondar esse valor:
No nosso exemplo, o sistema produz 250 KB de dados por segundo. Se ele mantiver esse ritmo durante aproximadamente 100.000 segundos, conseguimos estimar o volume diário.
Conta aproximada
1
Estimando o volume em KB
250 KB/s × 100.000 segundos = 25.000.000 KB
Multiplicamos a taxa de geração de dados pela quantidade aproximada de segundos em um dia.
2
Convertendo KB para GB
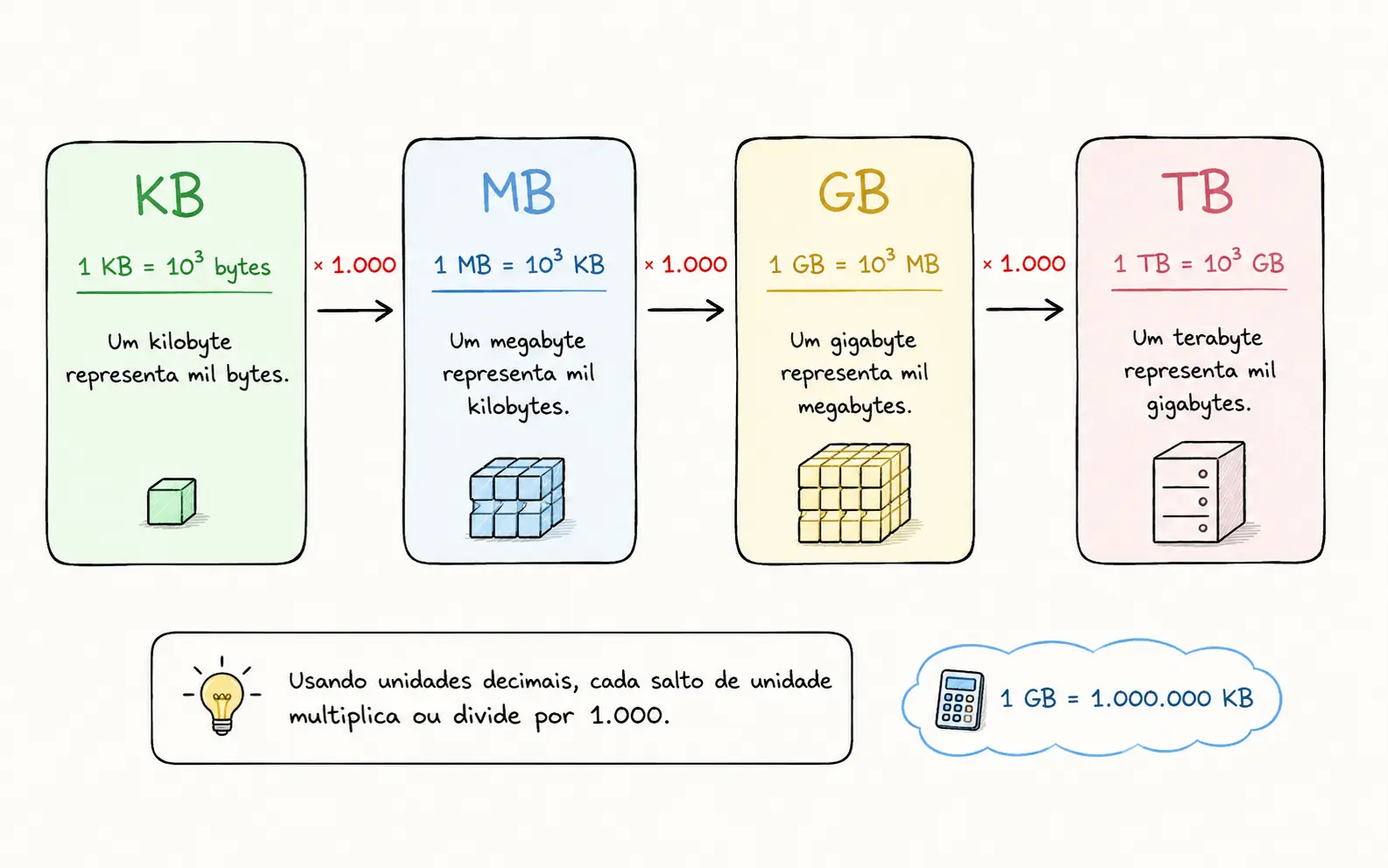
25.000.000 KB ÷ 1.000.000 = 25 GB por dia
Dividimos por 1.000.000 porque, em unidades decimais, 1 GB equivale a 1.000 MB e 1 MB equivale a 1.000 KB. Portanto, 1 GB = 1.000.000 KB.
3
Interpretando o resultado
25 GB por dia
O valor ainda é aproximado, mas a escala já ficou clara: estamos falando de dezenas de gigabytes produzidos por dia.
Essa estimativa usa 100.000 segundos como aproximação para um dia.
O importante aqui não é decorar potências de 10, e sim enxergar a escala do problema. Se você prefere fazer a conta com os números cheios — 250 × 100.000 — em vez de 10⁵, tudo bem: chega no mesmo lugar. O que não pode é a notação travar o raciocínio.
Na conta rápida, usamos 10⁵ segundos para representar um dia. Esse atalho nos levou a uma estimativa de 25 GB por dia.
Agora vamos refazer a mesma conta usando o valor real de segundos em um dia: 86.400.
Conta com segundos reais
1
Volume em KB
250 KB/s × 86.400 segundos = 21.600.000 KB
Aqui usamos a quantidade real de segundos em um dia, sem arredondar para 100.000.
2
Conversão para GB
21.600.000 KB ÷ 1.000.000 = 21,6 GB por dia
Dividimos por 1.000.000 porque, em unidades decimais, 1 GB equivale a 1.000.000 KB.
Com o atalho, chegamos a 25 GB/dia. Com os segundos reais, chegamos a 21,6 GB/dia.
A conclusão geral continua parecida: nos dois casos, o sistema está produzindo dezenas de gigabytes por dia. Mas isso não significa que a diferença sempre possa ser ignorada.
Estimativa rápida
Conta mais precisa
Diferença
25 GB/dia
Usando 10⁵ segundos como aproximação para um dia.
21,6 GB/dia
Usando os 86.400 segundos reais de um dia.
3,4 GB/dia
Pequena em um dia, mas relevante quando acumulada.
Estimativa rápida
25 GB/dia
Usando 10⁵ segundos como aproximação para um dia.
Conta mais precisa
Esse é o cuidado importante: uma diferença pequena por dia pode virar uma diferença grande quando acumulada. Aqueles 3,4 GB/dia viram cerca de 100 GB/mês e mais de 1 TB/ano — e isso ainda sem considerar replicação, backups, snapshots, índices, logs adicionais ou retenção maior.
Mesmo assim, usar 86.400 segundos não torna a estimativa perfeita. Ele apenas remove um arredondamento da conta.
Na prática, várias outras variáveis continuam mudando.
O sistema pode receber menos tráfego no fim de semana, ter picos em horário comercial, crescer em campanhas, datas específicas ou fechamento de mês. O tamanho médio dos dados também pode mudar conforme novos campos, logs, eventos e integrações entram no sistema.
Por isso, aproximação não significa descuido. Ela é uma primeira leitura da escala do problema, não uma garantia de capacidade.
Quando a decisão envolve orçamento de cloud, limite de disco, backup, , provisionamento ou compromisso com cliente, precisamos refinar a conta com métricas reais, padrões de tráfego e cenários mais próximos da produção.
A regra prática é simples:
Use aproximações para entender a escala e valores mais precisos para assumir compromissos.
Seguimos com 25 GB/dia como base para acompanhar a evolução da conta; quando a decisão envolver orçamento ou provisionamento, troque por uma medição real (como os 21,6 GB/dia).
Saber quanto dado o sistema produz por dia ainda não é suficiente.
Para manter a conta simples, vamos seguir com a estimativa rápida de 25 GB por dia. A próxima pergunta é: por quanto tempo esse volume precisa continuar armazenado?
Essa resposta muda completamente a estimativa. Guardar dados por 7 dias é uma coisa. Guardar dados por 1 ano é outra. Guardar por 5 anos já muda completamente o tamanho do problema.
Tempo de retenção é justamente isso: o período em que um dado precisa permanecer disponível antes de ser removido, arquivado ou movido para outro tipo de storage.
Retenção é uma política que define por quanto tempo cada tipo de dado será mantido.
Nem todo dado precisa ficar armazenado pelo mesmo período. Logs técnicos podem ter uma retenção curta. Eventos de auditoria podem precisar ficar por meses ou anos. Arquivos enviados por usuários talvez precisem existir enquanto a conta estiver ativa. Dados financeiros, fiscais ou contratuais podem depender de regras de negócio, suporte, compliance ou obrigações legais.
Alguns exemplos comuns:
Tipo de dado
Retenção típica
Por que esse prazo
Logs técnicos
7, 15, 30 ou 90 dias
Investigação, debug e observabilidade — nem sempre precisam ficar para sempre.
Auditoria
meses ou anos
Necessária para rastrear ações importantes no sistema.
Arquivos de usuário
enquanto fizer sentido para o produto
Dependem do plano, contrato, uso ou ciclo de vida da conta.
Dados fiscais ou contratuais
anos
Dependem de obrigações legais, contábeis ou regulatórias.
O ponto importante é: retenção não é apenas uma escolha técnica. Ela depende do produto, do negócio, da operação e, em alguns casos, de requisitos legais.
Por isso, antes de estimar storage, precisamos entender quais dados serão guardados e por quanto tempo.
Até aqui, chegamos a uma geração diária de aproximadamente 25 GB por dia.
Para descobrir o volume acumulado, multiplicamos esse valor pelo tempo de retenção.
Volume diário
Retenção
Storage lógico
25 GB/dia
×
30 dias
=
750 GB
Volume diário
25 GB/dia
×
Retenção
Agora o número começa a mudar de escala.
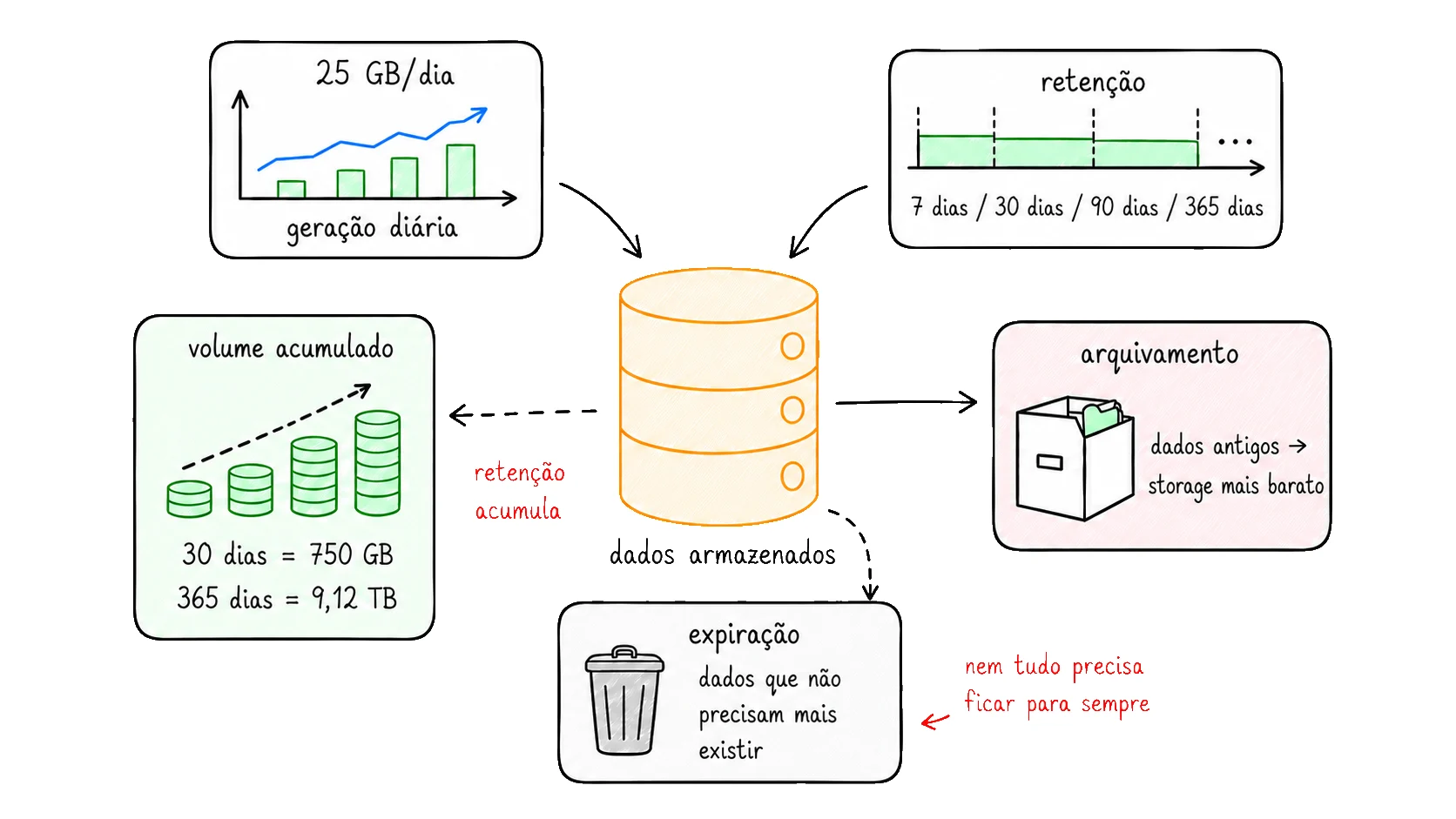
A taxa de 250 KB/s, que parecia pequena no começo, virou 25 GB por dia. Com apenas 30 dias de retenção, isso já representa 750 GB de dados lógicos acumulados.
Se a retenção for maior, o impacto cresce junto.
Retenção
Volume acumulado
O que isso representa
7 dias
175 GB
Retenção curta, comum para dados temporários.
30 dias
750 GB
Um mês de dados mantidos.
90 dias
2,25 TB
Três meses já levam a conta à escala de terabytes.
365 dias
9,12 TB
Um ano muda completamente a ordem de grandeza.
A mesma taxa de gravação pode gerar estimativas muito diferentes dependendo do tempo de retenção.
Essa é uma das partes mais importantes da estimativa: storage não cresce apenas porque o sistema recebe mais dados por segundo. Ele cresce porque esses dados permanecem acumulados.
Um erro comum é assumir que tudo que foi gravado precisa ficar para sempre no storage principal.
Na prática, sistemas maduros costumam separar os dados por idade, importância e frequência de acesso.
Dados recentes geralmente precisam ficar mais acessíveis, porque são consultados com mais frequência pelo produto, suporte, relatórios ou operação. Dados antigos podem ser arquivados, compactados, agregados ou movidos para um storage mais barato. Dados que não precisam mais existir podem ser removidos.
Uma estratégia simples para o ciclo de vida dos dados pode ser dividida em três camadas:
Dados recentes
Dados antigos
Dados expirados
banco principal
Mantidos em um storage mais rápido para consultas frequentes.
arquivamento
Movidos para um storage mais barato, para consulta eventual, auditoria ou histórico.
remoção segura
Eliminados quando não existe mais necessidade de retenção.
Dados recentes
banco principal
Mantidos em um storage mais rápido para consultas frequentes.
Dados antigos
Isso evita tratar todo dado da mesma forma.
Um log de debug antigo talvez não precise ocupar espaço no banco principal. Um evento analítico pode ser agregado depois de alguns meses. Um arquivo pouco acessado pode ir para uma camada de arquivamento. Um dado sensível pode exigir retenção mínima, não máxima.
A pergunta não é apenas:
quanto dado o sistema gera?
A pergunta correta é:
quanto dado precisa continuar disponível, em qual lugar, por quanto tempo e com qual nível de acesso?
Essa decisão muda custo, performance, backup, restore e complexidade operacional.
Por isso, tempo de retenção é uma das variáveis centrais da estimativa de storage. Ele transforma uma taxa diária em volume acumulado e prepara o próximo fator da conta: a replicação.
Com 25 GB por dia e 30 dias de retenção, chegamos a 750 GB. Esse número representa o tamanho dos dados como se existisse apenas uma cópia armazenada.
Mas muitos sistemas não mantêm apenas uma cópia.
Eles replicam os dados.
Replicação significa manter mais de uma cópia dos dados para aumentar disponibilidade, durabilidade ou tolerância a falhas.
Em vez de depender de um único disco, nó ou zona, o sistema mantém cópias adicionais. Assim, se uma parte da infraestrutura falhar, ainda existe outra cópia disponível.
O ponto importante para nossa estimativa é simples: cada cópia ocupa espaço.
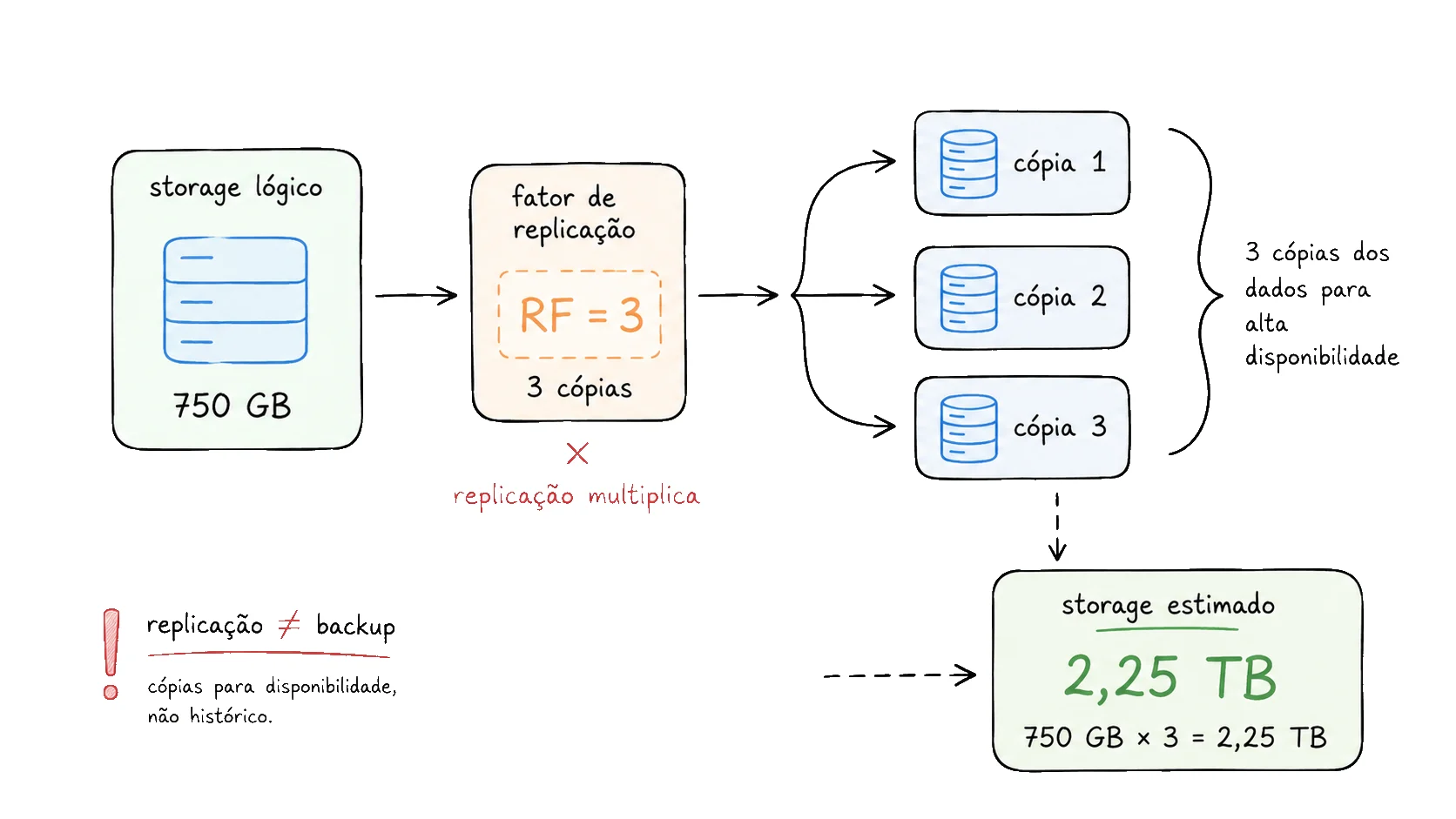
Se o volume lógico é 750 GB e o sistema mantém três cópias dos dados, a conta fica assim:
Storage lógico
Replicação
Storage estimado
750 GB
×
3 cópias
=
2,25 TB
Storage lógico
750 GB
×
Replicação
A mesma informação continua sendo gerada pelo sistema. O que mudou foi a quantidade de cópias mantidas para proteger e disponibilizar esses dados.
Por isso, replicação entra como um multiplicador na conta.
Storage lógico
Fator de replicação
Storage replicado
volume acumulado
×
número de cópias
=
volume estimado
Storage lógico
volume acumulado
×
Nesse exemplo, 750 GB parecia algo grande, mas ainda administrável. Com três cópias, o número já passa para 2,25 TB.
É aqui que muita estimativa inicial começa a ficar mais realista.
Replicação não é backup
Replicação protege contra falha de máquina, disco, nó ou zona — sempre há outra cópia pronta. Mas ela não protege contra erro humano, bug ou exclusão acidental: esses se propagam para todas as cópias. Backup é outra coisa: serve para recuperação histórica, com frequência, retenção e custo próprios.
Para a conta de storage, o que importa é que são coisas diferentes — replicação multiplica o volume ativo; backup é armazenamento à parte, com conta própria. Backup não entra nesta estimativa de propósito: frequência, retenção e política variam demais por empresa, contrato e compliance para caber numa conta rápida. Seguimos só com a replicação; os outros fatores aparecem nos cuidados finais.
A conta que fizemos ajuda a enxergar a ordem de grandeza, mas ela ainda não representa todo o consumo real de produção.
Alguns fatores podem aumentar, reduzir ou distorcer esse número:
Fator
Efeito no storage
Por quê
Índices
aumenta
Melhoram consultas, mas também ocupam espaço.
Backups e snapshots
aumenta
Criam cópias adicionais, com políticas próprias de retenção.
WAL, journal ou transaction log
aumenta
Bancos mantêm registros internos para recuperação e consistência.
Compressão
reduz
Pode reduzir o volume armazenado, dependendo do tipo de dado.
Picos de tráfego
distorce
A média diária pode esconder períodos de maior geração de dados.
Crescimento futuro
distorce
A conta de hoje pode não representar o volume daqui a seis meses.
Por isso, essa estimativa deve ser tratada como ponto de partida.
Ela ajuda a tomar decisões melhores, fazer perguntas mais cedo e evitar surpresas. Mas, antes de assumir orçamento, provisionar infraestrutura ou definir limites operacionais, o ideal é validar a conta com métricas reais do sistema.
Storage não costuma virar problema por causa de uma única gravação.
Ele vira problema pelo acúmulo: pequenos registros, eventos, logs e históricos que continuam sendo gerados todos os dias, durante semanas, meses ou anos.
A estimativa não precisa ser perfeita para ser útil. Começar com writes/s, tamanho médio, tempo de retenção e fator de replicação já ajuda a enxergar a ordem de grandeza antes que o crescimento vire custo, gargalo ou incidente.
Depois, com métricas reais, a conta pode ser refinada.
O importante é não tratar storage como infinito, nem deixar essa conversa para quando o alerta de disco já estiver gritando em produção.
Estimar storage é menos sobre acertar o número exato e mais sobre não ser pego de surpresa.
Fica o convite: da próxima vez que subir um serviço novo, rabisque essa conta de guardanapo antes do primeiro deploy. Cinco minutos agora poupam aquele susto na fatura lá na frente.
Tamanho médio
tamanho médio por gravação
=
Geração de dados
dados gerados por segundo
Tamanho médio
50 KB
=
Geração de dados
250 KB/s
Volume lógico produzido pelo sistema antes de considerar replicação, índices, backups, retenção ou estruturas internas do storage.
86.400 ≈ 100.000
Um número mais fácil de calcular mentalmente.
Notação científica
100.000 = 10⁵
Uma forma mais compacta de visualizar.
Para nossas estimativas rápidas: 1 dia ≈ 100.000 segundos ≈ 10⁵ segundos
21,6 GB/dia
Usando os 86.400 segundos reais de um dia.
Diferença
3,4 GB/dia
Pequena em um dia, mas relevante quando acumulada.
A aproximação ajuda a descobrir a escala. A conta mais precisa ajuda quando a diferença começa a afetar custo, limite de capacidade ou decisão operacional.
30 dias
=
Storage lógico
750 GB
Volume lógico acumulado antes de considerar replicação, backups, índices, snapshots ou overhead do storage.
arquivamento
Movidos para um storage mais barato, para consulta eventual, auditoria ou histórico.
Dados expirados
remoção segura
Eliminados quando não existe mais necessidade de retenção.
3 cópias
=
Storage estimado
2,25 TB
Estimativa considerando três cópias dos dados. Ainda não inclui backups, índices, snapshots, WAL, journal ou outros overheads internos.
Fator de replicação
número de cópias
=
Storage replicado
volume estimado
Volume diário
25 GB/dia
×
Retenção
30 dias
×
Replicação
3 cópias
=
Storage estimado
2,25 TB
A cadeia inteira de uma vez: do volume diário ao storage estimado — ainda sem considerar backups, índices, snapshots, WAL ou journal.
Questão1/5
Por que o RPS total não é uma boa base para estimar storage?